所有語言











分享
加密公地悲劇系列:Polymarket的數據索引之殤
陀螺科技_Lunc10天前
作者:shew
來源:GCC Research
摘要
歡迎來到 GCC Research 專欄的「加密公地悲劇」系列。
在這個系列中,我們將聚焦那些加密世界中處於關鍵節點卻逐漸失范的「公共物品」。它們是整個生態的基礎設施,但往往面臨激勵不足、治理失衡、甚至逐漸中心化的困境。加密技術所追求的理想和現實中的冗餘穩定性,正在這些角落裡經歷嚴峻的考驗。
本期,我們聚焦以太坊生態中最為「出圈」的應用之一:Polymarket 及其數據索引工具。尤其是今年以來,圍繞特朗普勝選、烏克蘭稀土交易的預言機操控、澤連斯基西服顏色的政治賭注等事件,使得 Polymarket 多次成為輿論焦點,它所承載的資金規模和市場影響力更是讓這些爭議變得不容忽視。
然而,這個代表「去中心化預測市場」的產品,它的關鍵基礎模塊——數據索引,真的實現了去中心化嗎?為什麼像 The Graph 這樣的公共基礎設施未能承擔起預期的角色?一個真正可用、可持續的數據索引公共物品,又應具備怎樣的形態?
一、一个中心化數據平台宕機引發的連鎖反應
2024 年 7 月,Goldsky 發生了長達六小時的宕機事故( Goldsky 是一家面向 Web3 開發者的實時區塊鏈數據基礎設施平台,提供索引、子圖與流式數據服務,幫助快速構建數據驅動的去中心化應用),導致以太坊生態系統的很大一部分項目陷入癱瘓,比如 DeFi 前端無法显示用戶的倉位以及餘額數據,預測市場 Polymarket 無法显示正確的數據,無數項目在前端用戶看來似乎已經完全無法使用。
這在去中心化應用的世界里本不應該發生。畢竟,區塊鏈技術的設計的最初目的不就是消除單點故障嗎?Goldsky 事件暴露了一個令人不安的事實:雖然區塊鏈本身已經盡可能實現了去中心化的,但是構建在鏈上的應用使用的基礎設施往往包含了大量的中心化服務。
究其原因,區塊鏈數據索引與檢索屬於「非排他、非競爭性」的数字公共產品,使用者往往期望免費或極低費率,但其背後卻需要持續投入高強度的硬件、存儲、帶寬與運維人力。缺乏可持續盈利模式時,就會出現贏家通吃的集中化格局:只要一家服務商在速度和資本上取得先發優勢,開發者便傾向把所有查詢流量導向該服務,從而重新形成單點依賴。Gitcoin 等公益項目已反覆強調,「開源基礎設施能創造數十億美元價值,但作者卻往往無法靠它償還房貸」 。
這警醒我們,去中心化世界迫切需要通過公共產品資助、再分配或社區驅動的舉措來豐富 Web3 基礎設施的多樣性,否則會出現中心化的問題。我們呼籲 DApp 開發者構建本地優先的產品,也呼籲技術社區在 DApp 設計時考慮數據檢索服務失效的情況,保證用戶在無數據檢索基礎設施的情況下仍可以與項目交互。
二、你在 Dapp 看到的數據,是從哪兒來的
要理解為什麼會發生 Goldsky 這樣的事件,我們需要深入了解 DApp 在幕後的工作機制。對普通用戶而言,DApp 通常只由兩部分構成:鏈上合約和前端頁面。大部分用戶已經習慣使用 Etherscan 等工具查找鏈上交易狀態,並在前端獲取必要信息,同時使用前端發起交易與合約交互。但這些在用戶前端显示的數據究竟從何而來?
不可或缺的數據檢索服務
假設讀者正在構建一個借貸協議,該協議需要显示用戶的持倉情況以及每個倉位的保證金和債務狀況。一個樸素的想法是前端直接從鏈上讀取這些數據。但在實踐中,借貸協議的合約不允許使用戶地址查詢倉位數據,合約會提供使用倉位 ID 查詢倉位的具體數據的函數。所以假如我們要在前端显示用戶的倉位情況,那麼我們需要把當前系統內所有的倉位都檢索出來,然後查找那些倉位屬於當前用戶。這就像要求某人手動搜索數百萬頁賬本來查找特定信息——技術上可行,但極其緩慢且低效。事實上,前端是很難完成這一檢索流程的,大型 DeFi 項目的檢索即使在服務器上直接依靠本地節點執行數據檢索任務往往也需要長達數小時的時間。
因此,我們必須引入基礎設施來加速數據獲取。Goldsky 等公司正是向用戶提供這些數據索引服務。下圖展示了數據索引服務可以為應用提供的數據類型。

在此處,可能有讀者好奇以太坊生態內似乎存在一個去中心化的數據檢索平台 TheGraph,該平台與 Goldsky 有哪些聯繫?以及為什麼大量的 DeFi 項目沒有使用更加去中心化的 TheGraph 而是使用 Goldsky 作為數據提供商?
TheGraph / Goldsky 與 SubGraph 的關係
要回答上述問題,我們需要先了解一些技術概念。
- SubGraph 是一個開發框架,開發者可以使用該框架編寫代碼來讀取並匯總鏈上數據,並且使用某些方法將這些數據讀取並显示到前端。
- TheGraph 是較早的去中心化數據檢索平台,該平台開發了使用 AssemblyScript 編寫的 SubGraph 框架,開發者可以使用 subgraph 框架編寫程序來捕獲合約事件並將這些合約事件寫入到數據庫中,之後用戶可以利用 Graphql 方法讀取這些數據或者直接利用 SQL 代碼讀取數據庫。
- 我們一般將運行 SubGraph 的服務提供商稱為 SubGraph 運營商。 TheGraph 和 Goldsky 實際上都是 SubGraph 的託管商。因為 SubGraph 只是一個開發框架,該框架開發出的程序需要在服務器內運行。我們可以看到 Goldsky 文檔內存在以下內容:
這裏可能有讀者好奇為什麼 SubGraph 存在多個運營商?
這是因為 SubGraph 框架其實只是約定了數據的如何從區塊內讀取和寫入數據庫。
對於數據如何流入 SubGraph 程序以及最終的輸出結果寫入到哪種數據庫其實都沒有進行實現,這些內容需要 SubGraph 運營商自己實現。
一般來說,SubGraph 運營商都會進行節點修改等實現更快的速度,不同的運營商(如 TheGraph,Goldsky )存在不同的策略和技術方案。
TheGraph 目前使用了 Firehouse 技術方案,該技術方案引入后,TheGraph 可以實現比過去更加快速的數據檢索,而 Goldsky 並沒有對外開源公開其 SubGraph 運行的核心程序。
正如上文所述,TheGraph 是一個去中心化的數據檢索平台,以 Unisawp v3 subgraph 為例,我們可以看到存在大量的運營商為 Uniswap v3 提供數據檢索,為次我們也可以將 TheGraph 視為一個 SubGraph 運營商的集成平台,用戶可以將自己編寫的 SubGraph 代碼發送給 TheGraph,然後 TheGraph 內部存在一些運營商可以幫助用戶檢索數據。
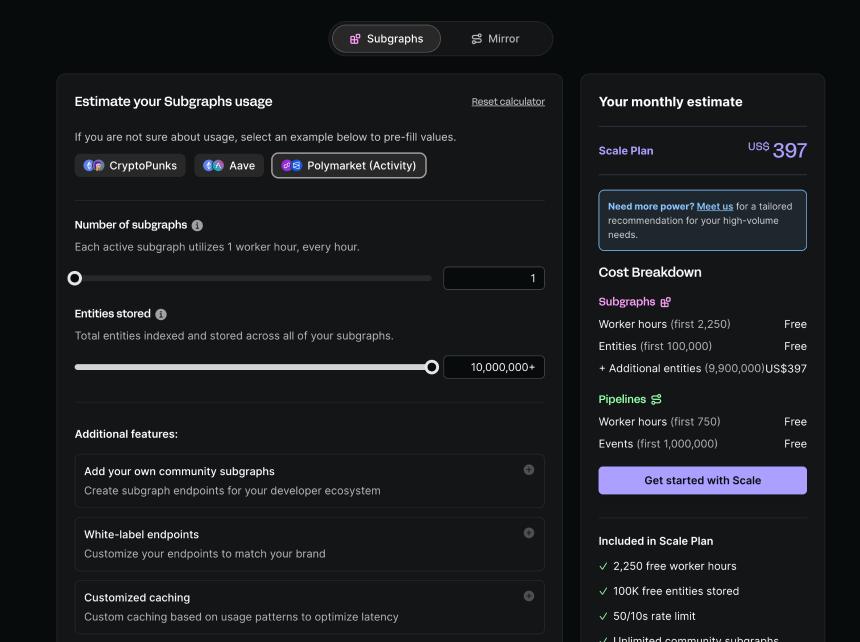
Goldsky 的收費模式
對於 Goldsky 這種集中化平台而言,Goldsky 存在一個簡單的計費標準,基於使用資源的計費,這是互聯網中最常見的 SaaS 平台的計費方式,大部份技術人員對對在這種方式十分熟悉。下圖展示了 Goldsky 的價格計算器:
TheGraph 的收費模式
TheGraph 則有一套完全與常規計費方式不同的費用方案,這套費用方案與 GRT 的代幣經濟學有關,下圖展示了 GRT 的整體代幣經濟學:
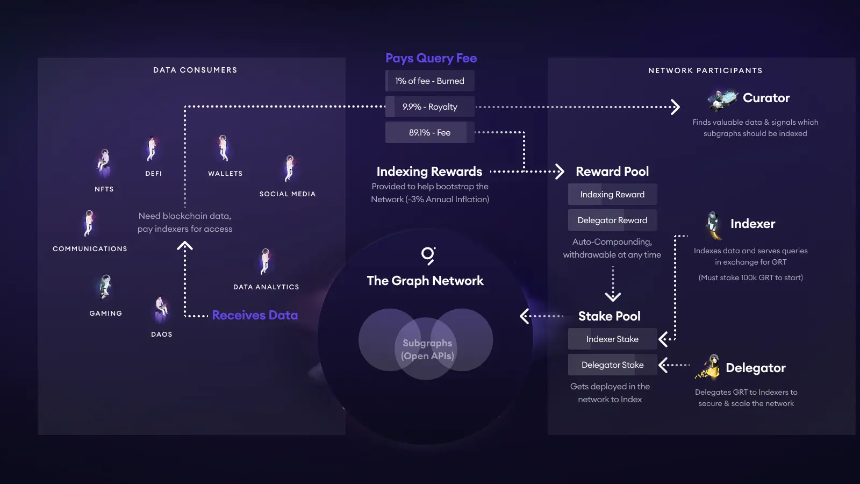
- 每當 DApp 或錢包向某個 Subgraph 發起請求,所付的 Query Fee 會被自動拆分:1 % 燒毀、約 10 % 流入該 Subgraph 的策展池(Curator / 開發者),其餘≈ 89 % 按指數返利機制打給提供算力的 Indexer 及其 Delegator。
- Indexer 要先自質押≥ 100 k GRT 才能上線;若返回錯誤數據將被懲罰(slashing)。Delegator 把 GRT 委託給 Indexer,按比例分得上述 89 % 的大頭。
- Curator(通常就是開發者)通過 Signal 在自家 Subgraph 的債券曲線上質押 GRT;Signal 數越高,越能吸引 Indexer 分配資源。社區經驗建議自籌 5 k–10 k GRT 可保證數個 Indexer 接單。與此同時,策展人還能拿到那 10 % Royalty。
TheGraph 的按次查詢費:
在 TheGraph 後台內註冊 API KEY,並使用該 API KEY 請求 TheGraph 內運營商檢索的數據,這部分請求是按照請求次數收費,開發者需要預先在平台內存入一部分 GRT 代幣作為 API 請求的開銷。
TheGraph 的 Signal 質押費:
對於 SubGraph 的部署者,需要 TheGraph 平台內的運營商幫助檢索數據,按照上面提到的收益分配方式,需要告訴其他參与者我的查詢服務更好,可以分到更多錢,就需要質押 GRT,類似於打廣告以及給自己擔保有收益,大家才會來。
測試的時候,開發者可以免費將 SubGraph 部署到 TheGraph 平台,此時 TheGraph 官方會幫助用戶進行一些檢索,提供一個用於測試的免費額度,並無法用於生產環境。如果開發者認為 SubGraph 在 TheGraph 官方的測試環境內運行良好,就可以將其發布到公開網絡內等待其他運營商參与檢索。開發者不能直接向某一個運營商付費,並獲得檢索的保障,而是讓多個運營商競相提供服務,避免形成單點依賴這。這個過程需要使用 GRT 代幣對自己的 SubGraph 進行策展 (Curating) 操作(也可以被稱為 Signal 操作),也就是開發者向自己部署的 SubGraph 內質押一定數量的 GRT,但質押的 GRT 數量到達一定量級(此前諮詢的數據是 10000 GRT) 時,運營商才加入 SubGraph 的檢索工作。
糟糕收費體驗,難倒開發者和傳統會計
對於大部份的項目開發者而言,使用 TheGraph 其實是一件相對麻煩的事情,購買 GRT 代幣對於 Web3 項目而言還算容易,但是對已部署的 SubGraph 進行 Curating 操作等待運營商的過程就是相當低效的環節。這一環節至少存在以下兩個問題:
- 質押 GRT 數量和吸引運營商所需時間的不確定性問題。筆者在過去部署 SubGraph 時直接諮詢了 TheGraph 的社區大使確定了質押 GRT 的數量,但是對於大部份開發者而言,這一數據並不好獲得,另外質押充足的 GRT 后,運營商介入檢索也需要一段時間
- 成本核算和會計的複雜性問題。由於 TheGraph 使用代幣經濟學機制設計收費標準,這對大部分開發者而言使成本計算變得複雜。更實際的問題是,如果企業要對該筆支出進行會計核算,會計可能也無法理解這部分成本構成。
「贊的,還是中心化的好?」
顯然,對於大部份開發者而言,直接選擇 Goldsky 是更加簡單的事情,計費方式所有人都可以理解,同時只要付費幾乎可以立即可用,不確定性大幅度降低,這也導致了區塊鏈數據索引與檢索服務上,出現了依賴於單一產品的情況。
顯然 TheGraph 複雜的 GRT 代幣經濟學影響了 TheGraph 的廣泛應用。代幣經濟學可以具有複雜性,但是顯然這些複雜性並不應該暴露給用戶,比如 GRT 的策展質押機制就不應該暴露給用戶,TheGraph 更好的手段是直接給用戶一個簡化的付費頁面。
上述對 TheGraph 的貶低並不是我個人的觀點,知名智能合約工程師與 Sablier 項目創始人 Paul Razvan Berg 也曾在 推文 內表達這一觀點。該推文提到發布 SubGraph 和 GRT 計費的用戶體驗是極其糟糕的。
三、一些現存的解決方案
對於數據檢索單點故障如何解決,上文內其實已經提到了一點,即開發者可以考慮使用 TheGraph 服務,只是流程會較為複雜,開發者需要買入 GRT 代幣進行質押策展和支付 API 費用。
目前,EVM 生態內存在大量數據檢索軟件,具體可以參考 Dune 編寫的 The State of EVM Indexing 或 rindexer 編寫的 EVM 數據檢索軟件匯總,另一個較新的討論可以參考 此推文。
此文並不會討論 Glodsky 的產生問題的具體原因,因為目前根據 Glodsky 報告 內的內容,Glodsky 知道具體的原因,但是只準備向企業級用戶披露具體原因。這意味任何第三方都無法在目前知道 Glodsky 到底發生何種故障。根據其報告內容可以推測,可能是檢索后的數據寫入數據庫時出現了問題,在這份 簡要報告 內,Glodsky 提及數據庫無法正常訪問,在與 AWS 合作后才獲得了數據庫的訪問權。
在本節中,我們主要介紹其他的解決方法:
- ponder 是一個簡單、開發體驗較好且部署簡便的數據檢索服務軟件,開發者可以自行租用服務器部署
- local-first 是一個有趣的開發理念,該理念呼籲開發者即使在缺失網絡的情況下仍可為用戶提供良好體驗。在存在區塊鏈的情況下,我們可以在某種程度上放寬 local-first 的限制,保證用戶在可以連接區塊鏈時就可以獲得良好體驗。
ponder
此處筆者為什麼推薦使用 ponder 而不是其他軟件?具體原因包含以下幾點:
- Ponder 沒有供應商依賴。最初 ponder 是個人開發者構建的項目,所以相比於其他企業提供的數據檢索軟件,ponder 只需要用戶填入以太坊 RPC URL 和 postgres 數據庫鏈接即可
- Ponder 提供良好的開發體驗,筆者在過去曾多次使用 ponder 進行開發,由於 ponder 是由 typescript 編寫,同時核心庫主要依賴 viem,開發體驗非常優秀
- Ponder 具有更高的性能
當然也會存在一些問題,ponder 目前其實仍處於快速開發時期,開發者可能會遇到由於版本破壞性更新導致之前項目無法運行的情況。考慮到本文並不是一篇技術入門文章,所以本文不會進一步討論 ponder 的開發細節,具有技術背景的讀者可以自行閱讀 文檔。
ponder 更有趣的細節是目前 ponder 也開始了部分商業化,但是 ponder 的商業化途徑與非常契合上一篇文章內討論的「隔離理論」。
在此處,我們簡單介紹「隔離理論」。我們認為公共物品的公共性使其可以服務任意多用戶,所以只要對公共物品收費就會導致部分用戶不再使用公共物品,此時社會利益並不是最大化的 ( 經濟學術語描述為「不再是帕累托最優」)。理論上,公共物品可以對每一個人進行區別定價來徵收費用,但是區別定價所花費的成本極有可能大於區別定價帶來的盈餘。所以公共物品免費開放的原因是並不是公共物品應該是天然免費,而是任何徵收固定費用的行為都會導致社會利益受損,並且目前沒有一種廉價的方法可以對每一個人進行區別定價。隔離理論提出了一種可以在公共物品內定價的方法,即通過某一種方法將一部份同質人群隔離出來,對這部分同質人群徵收費用。首先,隔離理論不會阻擋所有人對公共物品的免費享用,但是隔離理論提出了一種方法對部分人群徵收費用。
ponder 就是用了類似隔離理論的方法:
- 首先,ponder 的部署仍需要一定的知識,開發者在部署過程中需要提供 RPC 、數據庫等外部依賴。
- 同時在部署完成后,開發者需要持續運維 ponder 應用,比如使用 proxy 系統進行負載均衡避免數據請求影響 ponder 在後台線程內檢索鏈上數據。這些對於一般的開發者來說都稍有複雜。
- 目前 ponder 在內測全自動部署服務 marble,用戶只需要將代碼交付給該平台就可以實現自動部署。
顯然這是一種對「隔離理論」的應用,這些不願意自己運維 ponder 服務的開發者被隔離出來,這些開發者可以通過付費獲得 ponder 服務的簡化部署。當然,marble 平台的出現也沒有影響其他開發者免費使用 ponder 框架並且自託管部署。
ponder 和 Goldsky 的受眾?
- ponder 這種完全沒有供應商依賴的公共物品比其他依賴供應商的數據檢索服務在開發小型項目時更加流行。
- 某些運營有大型項目的開發者並不一定選擇 ponder 框架,因為大型項目往往要求檢索服務具有充分的性能,Goldsky 等服務提供商往往提供了充分的可用性保障。
兩者都存在一些風險點,從最近的 Goldsky 事件來看,開發者最好自行維護一套自己的 ponder 服務,以隨時應對可能的第三方服務宕機。以及使用 ponder 時可能要考慮 RPC 返回數據的有效性問題,不久前 safe 就報告了一次因為 RPC 返回錯誤數據導致檢索器崩潰的 情況。雖然沒有直接證據表明 Goldsky 事件也與 RPC 返回無效事件有關,但筆者懷疑 Goldsky 可能也遇到了類似事件。
local-first 開發理念
Local-first 是過去幾年一直被人討論的話題。簡單來說,Local-first 要求軟件具有以下功能:
- 離線工作
- 跨客戶端協同
目前大部份與 local-first 相關的技術討論都會涉及到 CRDT(Conflict-free Replicated Data Type) 技術,所謂 CRDT 是一種無衝突的數據格式,該格式允許用戶在多端操作時自動合併衝突以保持數據的完整性。一種簡單的看法是可以將 CRDT 視為一種帶有簡單共識協議的數據類型,在分佈式情況下,CRDT 可以保證數據的完整性和一致性。
但在區塊鏈開發中,我們可以放寬上述 Local-first 對軟件要求的限制。我們僅要求在沒有項目開發者提供的後端索引數據時,用戶在前端仍可以保持最低限度的可用性。同時,local-first 對跨客戶端協同的要求實際上已經由區塊鏈解決了。
在 DApp 的場景下,local-first 理念可以這樣實現:
- 緩存關鍵數據:前端應該緩存用戶的重要數據,如餘額、持倉信息等,即使索引服務不可用,用戶仍能看到最後已知的狀態。
- 降級功能設計:當後端索引服務不可用時,DApp 可以提供基礎功能,比如在數據檢索服務不可用時,部分數據可以考慮直接利用 RPC 讀取鏈上數據,可以保證用戶看到已有部分數據的最新情況
這種 local-first 的 DApp 設計理念能夠顯著提高應用的韌性,避免在數據檢索服務崩潰后的應用無法使用。在不考慮易用性的情況下,最好的 local-first 應用應該是要求用戶在本地運行節點,然後使用類似 trueblocks 的工具在本地檢索數據。關於去中心化檢索或本地檢索的一些討論,可以參考推文 Literally no one cares about decentralized frontends and indexers。
四、寫在最後
Goldsky 六小時宕機事件為生態敲響了警鐘。雖然區塊鏈本身具有去中心化和抗單點故障的特性,但構建在其上的應用生態系統仍然高度依賴中心化的基礎設施服務。這種依賴為整個生態系統帶來了系統性風險。
本文簡單介紹了早有盛名的去中心化檢索服務 TheGraph 為什麼在如今並沒有被廣泛使用,特別討論了 GRT 代幣經濟學帶來的一些複雜性。最後,本文討論了如何構建更加健壯的數據檢索基礎設施,筆者鼓勵開發者使用 ponder 自託管的數據檢索開發框架作為應急響應選項,同時也介紹 ponder 良好的商業化路徑。最後,本文討論 local-first 的開發理念,鼓勵開發者構建在無數據檢索服務下仍可使用的應用。
從目前來看,不少 Web3 的開發者都 意識 到了數據檢索服務的單點故障問題,GCC 希望更多開發者關注這一基礎設施,並嘗試構建去中心化的數據檢索服務或者設計一套框架使得 DApp 前端在無數據檢索服務的情況仍可運行。