所有語言











分享
OpenLedge 研報:數據與模型可變現的 AI 鏈
金色财经_Domino_Crypto18天前
作者:JacobZhao 來源:mirror
一、引言 | Crypto AI 的模型層躍遷
數據、模型與算力是 AI 基礎設施的三大核心要素,類比燃料(數據)、引擎(模型)、能源(算力)缺一不可。與傳統 AI 行業的基礎設施演進路徑類似,Crypto AI 領域也經歷了相似的階段。2024 年初,市場一度被去中心化 GPU 項目所主導 (Akash、Render、io.net 等 ),普遍強調「拼算力」的粗放式增長邏輯。而進入 2025 年後,行業關注點逐步上移至模型與數據層,標志著 Crypto AI 正從底層資源競爭過渡到更具可持續性與應用價值的中層構建。
通用大模型(LLM)vs 特化模型(SLM)
傳統的大型語言模型(LLM)訓練高度依賴大規模數據集與複雜的分佈式架構,參數規模動輒 70B~500B,訓練一次的成本常高達數百萬美元。而 SLM(Specialized Language Model)作為一種可復用基礎模型的輕量微調範式,通常基於 LLaMA、Mistral、DeepSeek 等開源模型,結合少量高質量專業數據及 LoRA 等技術,快速構建具備特定領域知識的專家模型,顯著降低訓練成本與技術門檻。
值得注意的是,SLM 並不會被集成進 LLM 權重中,而是通過 Agent 架構調用、插件系統動態路由、LoRA 模塊熱插拔、RAG(檢索增強生成)等方式與 LLM 協作運行。這一架構既保留了 LLM 的廣覆蓋能力,又通過精調模塊增強了專業表現,形成了高度靈活的組合式智能系統。
Crypto AI 在模型層的價值與邊界
Crypto AI 項目本質上難以直接提升大語言模型(LLM)的核心能力,核心原因在於
-
技術門檻過高:訓練 Foundation Model 所需的數據規模、算力資源與工程能力極其龐大,目前僅有美國(OpenAI 等)與中國(DeepSeek 等)等科技巨頭具備相應能力。
-
開源生態局限:雖然主流基礎模型如 LLaMA、Mixtral 已開源,但真正推動模型突破的關鍵依然集中於科研機構與閉源工程體系,鏈上項目在核心模型層的參与空間有限。
然而,在開源基礎模型之上,Crypto AI 項目仍可通過精調特化語言模型(SLM),並結合 Web3 的可驗證性與激勵機制實現價值延伸。作為 AI 產業鏈的「周邊接口層」,體現於兩個核心方向:
-
可信驗證層:通過鏈上記錄模型生成路徑、數據貢獻與使用情況,增強 AI 輸出的可追溯性與抗篡改能力。
-
激勵機制: 藉助原生 Token,用於激勵數據上傳、模型調用、智能體(Agent)執行等行為,構建模型訓練與服務的正向循環。
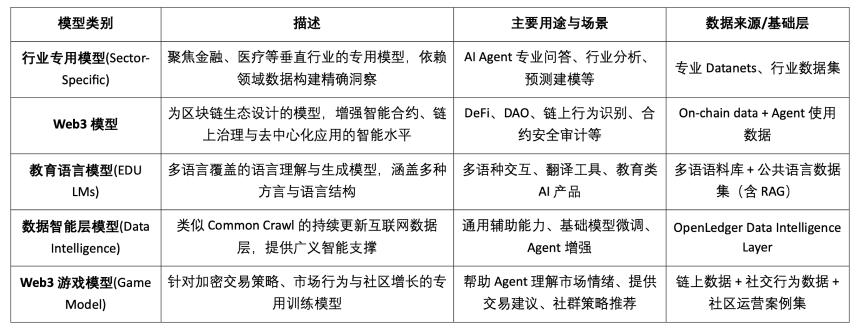
AI 模型類型分類與 區塊鏈適用性分析
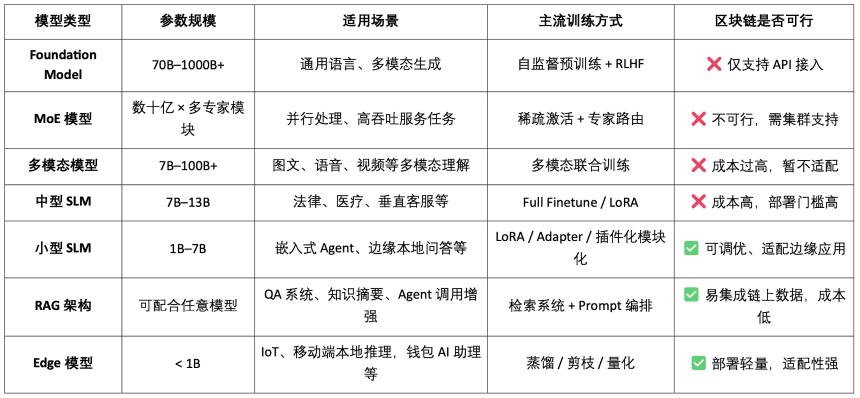
由此可見,模型類 Crypto AI 項目的可行落點主要集中在小型 SLM 的輕量化精調、RAG 架構的鏈上數據接入與驗證、以及 Edge 模型的本地部署與激勵上。結合區塊鏈的可驗證性與代幣機制,Crypto 能為這些中低資源模型場景提供特有價值,形成 AI「接口層」的差異化價值。
基於數據與模型的區塊鏈 AI 鏈,可對每一條數據和模型的貢獻來源進行清晰、不可篡改的上鏈記錄,顯著提升數據可信度與模型訓練的可溯性。同時,通過智能合約機制,在數據或模型被調用時自動觸發獎勵分發,將 AI 行為轉化為可計量、可交易的代幣化價值,構建可持續的激勵體系。此外,社區用戶還可通過代幣投票評估模型性能、參与規則制定與迭代,完善去中心化治理架構。
二、項目概述 | OpenLedger 的 AI 鏈願景
OpenLedger 是當前市場上為數不多專註於數據與模型激勵機制的區塊鏈 AI 項目。它率先提出「Payable AI」的概念,旨在構建一個公平、透明且可組合的 AI 運行環境,激勵數據貢獻者、模型開發者與 AI 應用構建者在同一平台協作,並根據實際貢獻獲得鏈上收益。
OpenLedger 提供了從「數據提供」到「模型部署」再到「調用分潤」的全鏈條閉環,其核心模塊包括:
-
Model Factory:無需編程,即可基於開源 LLM 使用 LoRA 微調訓練並部署定製模型;
-
OpenLoRA:支持千模型共存,按需動態加載,顯著降低部署成本;
-
PoA(Proof of Attribution):通過鏈上調用記錄實現貢獻度量與獎勵分配;
-
Datanets:面向垂類場景的結構化數據網絡,由社區協作建設與驗證;
-
模型提案平台(Model Proposal Platform):可組合、可調用、可支付的鏈上模型市場。
通過以上模塊,OpenLedger 構建了一個數據驅動、模型可組合的「智能體經濟基礎設施」,推動 AI 價值鏈的鏈上化。
而在區塊鏈技術採用上,OpenLedger 以 OP Stack + EigenDA 為底座,為 AI 模型構建了高性能、低成本、可驗證的數據與合約運行環境。
-
基於 OP Stack 構建: 基於 Optimism 技術棧,支持高吞吐與低費用執行;
-
在以太坊主網上結算: 確保交易安全性與資產完整性;
-
EVM 兼容: 方便開發者基於 Solidity 快速部署與擴展;
-
EigenDA 提供數據可用性支持:顯著降低存儲成本,保障數據可驗證性。
相比於 NEAR 這類更偏底層、主打數據主權與 「AI Agents on BOS」 架構的通用型 AI 鏈,OpenLedger 更專註於構建面向數據與模型激勵的 AI 專用鏈,致力於讓模型的開發與調用在鏈上實現可追溯、可組合與可持續的價值閉環。它是 Web3 世界中的模型激勵基礎設施,結合 HuggingFace 式的模型託管、Stripe 式的使用計費與 Infura 式的鏈上可組合接口,推動「模型即資產」的實現路徑。
三、OpenLedger 的核心組件與技術架構
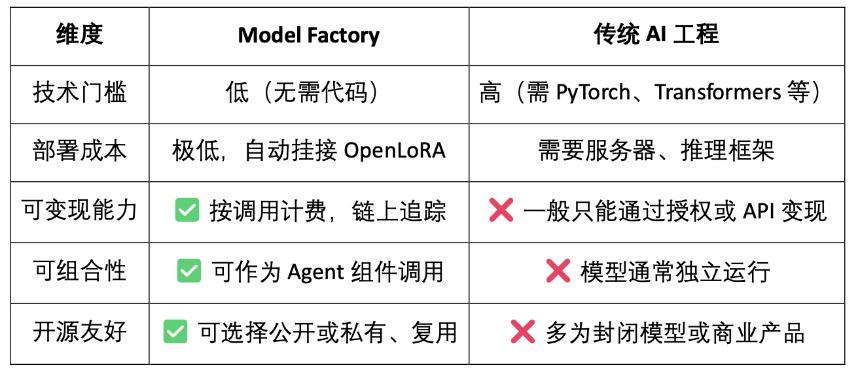
3.1 Model Factory,無需代碼模型工廠
ModelFactory 是 OpenLedger 生態下的一個大型語言模型(LLM)微調平台。與傳統微調框架不同,ModelFactory 提供純圖形化界面操作,無需命令行工具或 API 集成。用戶可以基於在 OpenLedger 上完成授權與審核的數據集,對模型進行微調。實現了數據授權、模型訓練與部署的一體化工作流,其核心流程包括:
-
數據訪問控制: 用戶提交數據請求,提供者審核批准,數據自動接入模型訓練界面。
-
模型選擇與配置: 支持主流 LLM(如 LLaMA、Mistral),通過 GUI 配置超參數。
-
輕量化微調: 內置 LoRA / QLoRA 引擎,實時展示訓練進度。
-
模型評估與部署: 內建評估工具,支持導出部署或生態共享調用。
-
交互驗證接口: 提供聊天式界面,便於直接測試模型問答能力。
-
RAG 生成溯源: 回答帶來源引用,增強信任與可審計性。
Model Factory 系統架構包含六大模塊,貫穿身份認證、數據權限、模型微調、評估部署與 RAG 溯源,打造安全可控、實時交互、可持續變現的一體化模型服務平台。
ModelFactory 目前支持的大語言模型能力簡表如下:
-
LLaMA 系列:生態最廣、社區活躍、通用性能強,是當前最主流的開源基礎模型之一。
-
Mistral:架構高效、推理性能極佳,適合部署靈活、資源有限的場景。
-
Qwen:阿里出品,中文任務表現優異,綜合能力強,適合國內開發者首選。
-
ChatGLM:中文對話效果突出,適合垂類客服和本地化場景。
-
Deepseek:在代碼生成和數學推理上表現優越,適用於智能開發輔助工具。
-
Gemma:Google 推出的輕量模型,結構清晰,易於快速上手與實驗。
-
Falcon:曾是性能標杆,適合基礎研究或對比測試,但社區活躍度已減。
-
BLOOM:多語言支持較強,但推理性能偏弱,適合語言覆蓋型研究。
-
GPT-2:經典早期模型,僅適合教學和驗證用途,不建議實際部署使用。
雖然 OpenLedger 的模型組合併未包含最新的高性能 MoE 模型或多模態模型,但其策略並不落伍,而是基於鏈上部署的現實約束(推理成本、RAG 適配、LoRA 兼容、EVM 環境)所做出的「實用優先」配置。
Model Factory 作為無代碼工具鏈,所有模型都內置了貢獻證明機制,確保數據貢獻者和模型開發者的權益,具有低門檻、可變現與可組合性的優點,與傳統模型開發工具相比較:
-
對於開發者:提供模型孵化、分發、收入的完整路徑;
-
對於平台:形成模型資產流通與組合生態;
-
對於應用者:可以像調用 API 一樣組合使用模型或 Agent。
3.2 OpenLoRA,微調模型的鏈上資產化
LoRA(Low-Rank Adaptation)是一種高效的參數微調方法,通過在預訓練大模型中插入「低秩矩陣」來學習新任務,而不修改原模型參數,從而大幅降低訓練成本和存儲需求。傳統大語言模型(如 LLaMA、GPT-3)通常擁有數十億甚至千億參數。要將它們用於特定任務(如法律問答、醫療問診),就需要進行微調(fine-tuning)。LoRA 的核心策略是:「凍結原始大模型的參數,只訓練插入的新參數矩陣。」,其參數高效、訓練快速、部署靈活,是當前最適合 Web3 模型部署與組合調用的主流微調方法。
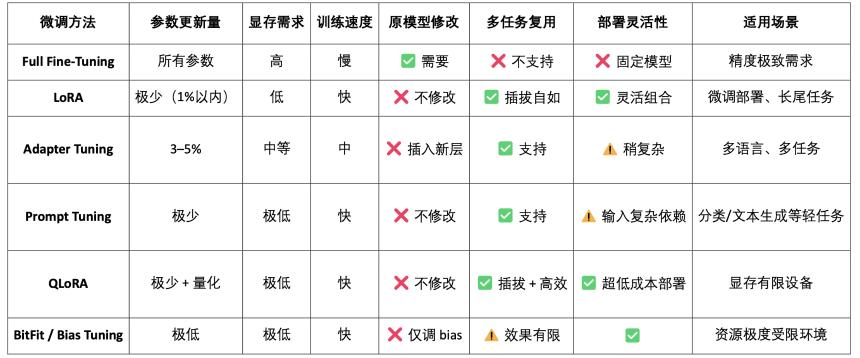
OpenLoRA 是 OpenLedger 構建的一套專為多模型部署與資源共享而設計的輕量級推理框架。它核心目標是解決當前 AI 模型部署中常見的高成本、低復用、GPU 資源浪費等問題,推動「可支付 AI」(Payable AI)的落地執行。
OpenLoRA 系統架構核心組件,基於模塊化設計,覆蓋模型存儲、推理執行、請求路由等關鍵環節,實現高效、低成本的多模型部署與調用能力:
-
LoRA Adapter 存儲模塊 (LoRA Adapters Storage):微調后的 LoRA adapter 被託管在 OpenLedger 上,實現按需加載,避免將所有模型預載入顯存,節省資源。
-
模型託管與動態融合層 (Model Hosting & Adapter Merging Layer):所有微調模型共用基礎大模型(base model),推理時 LoRA adapter 動態合併,支持多個 adapter 聯合推理(ensemble),提升性能。
-
推理引擎(Inference Engine):集成 Flash-Attention、Paged-Attention、SGMV 優化等多項 CUDA 優化技術。
-
請求路由與流式輸出模塊 (Request Router & Token Streaming): 根據請求中所需模型動態路由至正確 adapter, 通過優化內核實現 token 級別的流式生成。
OpenLoRA 的推理流程屬於技術層面「成熟通用」的模型服務「流程,如下:
-
基礎模型加載:系統預加載如 LLaMA 3、Mistral 等基礎大模型至 GPU 顯存中。
-
LoRA 動態檢索:接收請求后,從 Hugging Face、Predibase 或本地目錄動態加載指定 LoRA adapter。
-
適配器合併激活:通過優化內核將 adapter 與基礎模型實時合併,支持多 adapter 組合推理。
-
推理執行與流式輸出:合併后的模型開始生成響應,採用 token 級流式輸出降低延遲,結合量化保障效率與精度。
-
推理結束與資源釋放:推理完成后自動卸載 adapter,釋放顯存資源。確保可在單 GPU 上高效輪轉並服務數千個微調模型,支持模型高效輪轉。
OpenLoRA 通過一系列底層優化手段,顯著提升了多模型部署與推理的效率。其核心包括動態 LoRA 適配器加載(JIT loading),有效降低顯存佔用;張量并行(Tensor Parallelism)與 Paged Attention 實現高併發與長文本處理;支持多模型融合(Multi-Adapter Merging)多適配器合併執行,實現 LoRA 組合推理(ensemble);同時通過 Flash Attention、預編譯 CUDA 內核和 FP8/INT8 量化技術,對底層 CUDA 優化與量化支持,進一步提升推理速度並降低延遲。這些優化使得 OpenLoRA 能在單卡環境下高效服務數千個微調模型,兼顧性能、可擴展性與資源利用率。
OpenLoRA 定位不僅是一個高效的 LoRA 推理框架,更是將模型推理與 Web3 激勵機制深度融合,目標是將 LoRA 模型變成可調用、可組合、可分潤的 Web3 資產。
-
模型即資產(Model-as-Asset):OpenLoRA 不只是部署模型,而是賦予每個微調模型鏈上身份(Model ID),並將其調用行為與經濟激勵綁定,實現「調用即分潤」。
-
多 LoRA 動態合併 + 分潤歸屬:支持多個 LoRA adapter 的動態組合調用,允許不同模型組合形成新的 Agent 服務,同時系統可基於 PoA(Proof of Attribution)機制按調用量為每個適配器精確分潤。
-
支持長尾模型的「多租戶共享推理」:通過動態加載與顯存釋放機制,OpenLoRA 能在單卡環境下服務數千個 LoRA 模型,特別適合 Web3 中小眾模型、個性化 AI 助手等高復用、低頻調用場景。
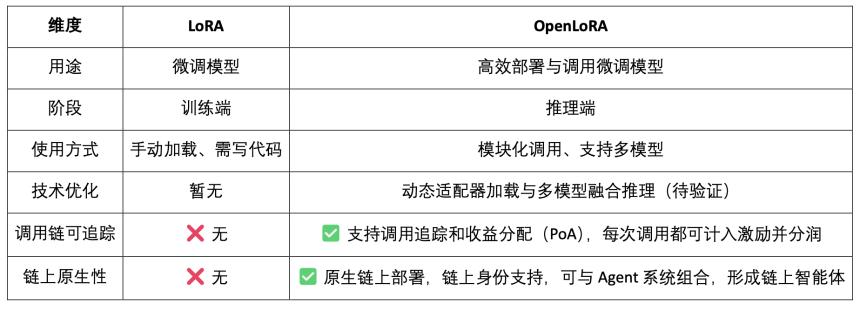
此外,OpenLedger 發布了其對 OpenLoRA 性能指標的未來展望,相比傳統全參數模型部署,其顯存佔用大幅降低至 8–12GB;模型切換時間理論上可低於 100ms;吞吐量可達 2000+ tokens/sec;延遲控制在 20–50ms 。整體而言,這些性能指標在技術上具備可達性,但更接近「上限表現」,在實際生產環境中,性能表現可能會受到硬件、調度策略和場景複雜度的限制,應被視為「理想上限」而非「穩定日常」。
3.3 Datanets(數據網絡),從數據主權到數據智能
高質量、領域專屬的數據成為構建高性能模型的關鍵要素。Datanets 是 OpenLedger 」數據即資產「的基礎設施,用於收集和管理特定領域的數據集,用於聚合、驗證與分發特定領域數據的去中心化網絡,為 AI 模型的訓練與微調提供高質量數據源。每個 Datanet 就像一個結構化的數據倉庫,由貢獻者上傳數據,並通過鏈上歸屬機制確保數據可溯源、可信任,通過激勵機制與透明的權限控制,Datanets 實現了模型訓練所需數據的社區共建與可信使用。
與聚焦數據主權的 Vana 等項目相比,OpenLedger 並不止於「數據收集」,而是通過 Datanets(協作式標註與歸屬數據集)、Model Factory(支持無代碼微調的模型訓練工具)、OpenLoRA(可追蹤、可組合的模型適配器)三大模塊,將數據價值延展至模型訓練與鏈上調用,構建「從數據到智能(data-to-intelligence)」的完整閉環。Vana 強調「誰擁有數據」,而 OpenLedger 則聚焦「數據如何被訓練、調用並獲得獎勵」,在 Web3 AI 生態中分別佔據數據主權保障與數據變現路徑的關鍵位置。
3.4 Proof of Attribution(貢獻證明):重塑利益分配的激勵層
Proof of Attribution(PoA)是 OpenLedger 實現數據歸屬與激勵分配的核心機制,通過鏈上加密記錄,將每一條訓練數據與模型輸出建立可驗證的關聯,確保貢獻者在模型調用中獲得應得回報,其數據歸屬與激勵流程概覽如下:
-
數據提交:用戶上傳結構化、領域專屬的數據集,並上鏈確權。
-
影響評估:系統根據數據特徵影響與貢獻者聲譽,在每次推理時評估其價值。
-
訓練驗證:訓練日誌記錄每條數據的實際使用情況,確保貢獻可驗證。
-
激勵分配:根據數據影響力,向貢獻者發放與效果掛鈎的 Token 獎勵。
-
質量治理:對低質、冗餘或惡意數據進行懲罰,保障模型訓練質量。
與 Bittensor 子網架構結合評分機制的區塊鏈通用型激勵網絡相比較,OpenLedger 則專註於模型層面的價值捕獲與分潤機制。PoA 不僅是一個激勵分發工具,更是一個面向 透明度、來源追蹤與多階段歸屬 的框架:它將數據的上傳、模型的調用、智能體的執行過程全程上鏈記錄,實現端到端的可驗證價值路徑。這種機制使得每一次模型調用都能溯源至數據貢獻者與模型開發者,從而實現鏈上 AI 系統中真正的「價值共識」與「收益可得」。
RAG(Retrieval-Augmented Generation) 是一種結合檢索系統與生成式模型的 AI 架構,它旨在解決傳統語言模型「知識封閉」「胡編亂造」的問題,通過引入外部知識庫增強模型生成能力,使輸出更加真實、可解釋、可驗證。RAG Attribution 是 OpenLedger 在檢索增強生成(Retrieval-Augmented Generation)場景下建立的數據歸屬與激勵機制,確保模型輸出的內容可追溯、可驗證,貢獻者可激勵,最終實現生成可信化與數據透明化,其流程包括:
-
用戶提問 → 檢索數據:AI 接收到問題后,從 OpenLedger 數據索引中檢索相關內容。
-
數據被調用並生成回答:檢索到的內容被用於生成模型回答,並被鏈上記錄調用行為。
-
貢獻者獲得獎勵:數據被使用后,其貢獻者獲得按金額與相關性計算的激勵。
-
生成結果帶引用:模型輸出附帶原始數據來源鏈接,實現透明問答與可驗證內容。

OpenLedger 的 RAG Attribution 讓每一次 AI 回答都可追溯至真實數據來源,貢獻者按引用頻次獲得激勵,實現「知識有出處、調用可變現」。這一機制不僅提升了模型輸出的透明度,也為高質量數據貢獻構建了可持續的激勵閉環,是推動可信 AI 和數據資產化的關鍵基礎設施。
四、OpenLedger 項目進展與生態合作
目前 OpenLedger 已上線測試網,數據智能層 (Data Intelligence Layer) 是 OpenLedger 測試網的首個階段,旨在構建一個由社區節點共同驅動的互聯網數據倉庫。這些數據經過篩選、增強、分類和結構化處理,最終形成適用於大型語言模型(LLM)的輔助智能,用於構建 OpenLedger 上的領域 AI 模型。社區成員可運行邊緣設備節點,參与數據採集與處理,節點將使用本地計算資源執行數據相關任務,參与者根據活躍度和任務完成度獲得積分獎勵。而這些積分將在未來轉換為 OPEN 代幣,具體兌換比例將在代幣生成事件(TGE)前公布。
OpenLedger 測試網激勵目前提供如下三類收益機制:

Epoch 2 測試網重點推出了 Datanets 數據網絡機制,該階段僅限白名單用戶參与,需完成預評估以解鎖任務。任務涵蓋數據驗證、分類等,完成后根據準確率和難度獲得積分,並通過排行榜激勵高質量貢獻,官網目前提供的可參与數據模型如下:
而 OpenLedger 更為長遠的路線圖規劃,從數據採集、模型構建走向 Agent 生態,逐步實現「數據即資產、模型即服務、Agent 即智能體」的完整去中心化 AI 經濟閉環。
-
Phase 1 · 數據智能層 (Data Intelligence Layer): 社區通過運行邊緣節點採集和處理互聯網數據,構建高質量、持續更新的數據智能基礎層。
-
Phase 2 · 社區數據貢獻 (Community Contributions): 社區參与數據驗證與反饋,共同打造可信的黃金數據集(Golden Dataset),為模型訓練提供優質輸入。
-
Phase 3 · 模型構建與歸屬聲明 (Build Models & Claim): 基於黃金數據,用戶可訓練專用模型並確權歸屬,實現模型資產化與可組合的價值釋放。
-
Phase 4 · 智能體創建 (Build Agents): 基於已發布模型,社區可創建個性化智能體(Agents),實現多場景部署與持續協同演進。
OpenLedger 的生態合作夥伴涵蓋算力、基礎設施、工具鏈與 AI 應用。其合作夥伴包括 Aethir、Ionet、0G 等去中心化算力平台,AltLayer、Etherfi 及 EigenLayer 上的 AVS 提供底層擴容與結算支持;Ambios、Kernel、Web3Auth、Intract 等工具提供身份驗證與開發集成能力;在 AI 模型與智能體方面,OpenLedger 聯合 Giza、Gaib、Exabits、FractionAI、Mira、NetMind 等項目共同推進模型部署與智能體落地,構建一個開放、可組合、可持續的 Web3 AI 生態系統。
過去一年,OpenLedger 在 Token2049 Singapore、Devcon Thailand、Consensus Hong Kong 及 ETH Denver 期間連續主辦 Crypto AI 主題的 DeAI Summit 峰會,邀請了眾多去中心化 AI 領域的核心項目與技術領袖參与。作為少數能夠持續策劃高質量行業活動的基礎設施項目之一,OpenLedger 藉助 DeAI Summit 有效強化了其在開發者社區與 Web3 AI 創業生態中的品牌認知與專業聲譽,為其後續生態拓展與技術落地奠定了良好的行業基礎。
五、融資及團隊背景
OpenLedger 於 2024 年 7 月完成了 1120 萬美元的種子輪融資,投資方包括 Polychain Capital、Borderless Capital、Finality Capital、Hashkey,以及多位知名天使投資人,如 Sreeram Kannan(EigenLayer)、Balaji Srinivasan、Sandeep(Polygon)、Kenny(Manta)、Scott(Gitcoin)、Ajit Tripathi(Chainyoda)和 Trevor。資金將主要用於推進 OpenLedger 的 AI Chain 網絡建設、模型激勵機制、數據基礎層及 Agent 應用生態的全面落地。

OpenLedger 由 Ram Kumar 創立,他是 OpenLedger 的核心貢獻者,同時是一位常駐舊金山的創業者,在 AI/ML 和區塊鏈技術領域擁有堅實的技術基礎。他為項目帶來了市場洞察力、技術專長與戰略領導力的有機結合。Ram 曾聯合領導一家區塊鏈與 AI/ML 研發公司,年營收超過 3500 萬美元,並在推動關鍵合作方面發揮了重要作用,其中包括與沃爾瑪子公司達成的一項戰略合資項目。他專註於生態系統構建與高槓桿合作,致力於加速各行業的現實應用落地。
六、代幣經濟模型設計及治理
OPEN 是 OpenLedger 生態的核心功能型代幣,賦能網絡治理、交易運行、激勵分發與 AI Agent 運營,是構建 AI 模型與數據在鏈上可持續流通的經濟基礎,目前官方公布的代幣經濟學尚屬早期設計階段,細節尚未完全明確,但隨着項目即將邁入代幣生成事件(TGE)階段,其社區增長、開發者活躍度與應用場景實驗正在亞洲、歐洲與中東地區持續加速推進:
-
治理與決策:OPEN 持有者可參与模型資助、Agent 管理、協議升級與資金使用的治理投票。
-
交易燃料與費用支付:作為 OpenLedger 網絡的原生 gas 代幣,支持 AI 原生的定製費率機制。
-
激勵與歸屬獎勵:貢獻高質量數據、模型或服務的開發者可根據使用影響獲得 OPEN 分潤。
-
跨鏈橋接能力:OPEN 支持 L2 ↔ L1(Ethereum)橋接,提升模型和 Agent 的多鏈可用性。
-
AI Agent 質押機制:AI Agent 運行需質押 OPEN,表現不佳將被削減質押,激勵高效、可信的服務輸出。
與許多影響力與持幣數量掛鈎的代幣治理協議不同,OpenLedger 引入了一種基於貢獻價值的治理機制。其投票權重與實際創造的價值相關,而非單純的資本權重,優先賦能那些參与模型和數據集構建、優化與使用的貢獻者。這種架構設計有助於實現治理的長期可持續性,防止投機行為主導決策,真正契合其「透明、公平、社區驅動」的去中心化 AI 經濟願景。
七、數據、模型與激勵市場格局及競品比較
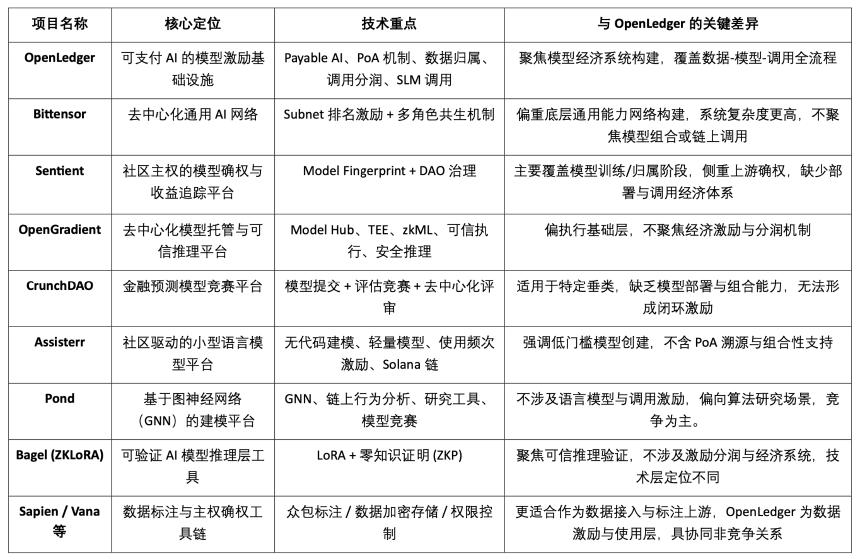
OpenLedger 作為「可支付 AI(Payable AI)」模型激勵基礎設施,致力於為數據貢獻者與模型開發者提供可驗證、可歸屬、可持續的價值變現路徑。其圍繞鏈上部署、調用激勵和智能體組合機制,構建出具有差異化特徵的模塊體系,在當前 Crypto AI 賽道中獨樹一幟。雖然尚無項目在整體架構上完全重合,但在協議激勵、模型經濟與數據確權等關鍵維度,OpenLedger 與多個代表性項目呈現出高度可比性與協作潛力。
協議激勵層:OpenLedger vs. Bittensor
Bittensor 是當前最具代表性的去中心化 AI 網絡,構建了由子網(Subnet)和評分機制驅動的多角色協同系統,以 $TAO 代幣激勵模型、數據與排序節點等參与者。相比之下,OpenLedger 專註於鏈上部署與模型調用的收益分潤,強調輕量化架構與 Agent 協同機制。兩者激勵邏輯雖有交集,但目標層級與系統複雜度差異明顯:Bittensor 聚焦通用 AI 能力網絡底座,OpenLedger 則定位為 AI 應用層的價值承接平台。
模型歸屬與調用激勵:OpenLedger vs. Sentient
Sentient 提出的 「OML(Open, Monetizable, Loyal)AI」理念在模型確權與社區所有權上與 OpenLedger 部分思路相似,強調通過 Model Fingerprinting 實現歸屬識別與收益追蹤。不同之處在於,Sentient 更聚焦模型的訓練與生成階段,而 OpenLedger 專註於模型的鏈上部署、調用與分潤機制,二者分別位於 AI 價值鏈的上游與下游,具有天然互補性。
模型託管與可信推理平台:OpenLedger vs. OpenGradient
OpenGradient 側重構建基於 TEE 和 zkML 的安全推理執行框架,提供去中心化模型託管與推理服務,聚焦於底層可信運行環境。相比之下,OpenLedger 更強調鏈上部署后的價值捕獲路徑,圍繞 Model Factory、OpenLoRA、PoA 與 Datanets 構建「訓練—部署—調用—分潤」的完整閉環。兩者所處模型生命周期不同:OpenGradient 偏運行可信性,OpenLedger 偏收益激勵與生態組合,具備高度互補空間。
眾包模型與評估激勵:OpenLedger vs. CrunchDAO
CrunchDAO 專註於金融預測模型的去中心化競賽機制,鼓勵社區提交模型並基於表現獲得獎勵,適用於特定垂直場景。相較之下,OpenLedger 提供可組合模型市場與統一部署框架,具備更廣泛的通用性與鏈上原生變現能力,適合多類型智能體場景拓展。兩者在模型激勵邏輯上互補,具備協同潛力。
社區驅動輕量模型平台:OpenLedger vs. Assisterr
Assisterr 基於 Solana 構建,鼓勵社區創建小型語言模型(SLM),並通過無代碼工具與 $sASRR 激勵機制提升使用頻率。相較而言,OpenLedger 更強調數據 - 模型 - 調用的閉環追溯與分潤路徑,藉助 PoA 實現細粒度激勵分配。Assisterr 更適合低門檻的模型協作社區,OpenLedger 則致力於構建可復用、可組合的模型基礎設施。
模型工廠:OpenLedger vs. Pond
Pond 與 OpenLedger 同樣提供「Model Factory」模塊,但定位與服務對象差異顯著。Pond 專註基於圖神經網絡(GNN)的鏈上行為建模,主要面向算法研究者與數據科學家,並通過競賽機制推動模型開發,Pond 更加傾向於模型競爭;OpenLedger 則基於語言模型微調(如 LLaMA、Mistral),服務開發者與非技術用戶,強調無代碼體驗與鏈上自動分潤機制,構建數據驅動的 AI 模型激勵生態,OpenLedger 更加傾向於數據合作。
可信推理路徑:OpenLedger vs. Bagel
Bagel 推出了 ZKLoRA 框架,利用 LoRA 微調模型與零知識證明(ZKP)技術,實現鏈下推理過程的加密可驗證性,確保推理執行的正確性。而 OpenLedger 則通過 OpenLoRA 支持 LoRA 微調模型的可擴展部署與動態調用,同時從不同角度解決推理可驗證性問題 —— 它通過為每次模型輸出附加歸屬證明(Proof of Attribution, PoA),追蹤推理所依賴的數據來源及其影響力。這不僅提升了透明度,還為高質量數據貢獻者提供獎勵,並增強了推理過程的可解釋性與可信度。簡言之,Bagel 注重計算結果的正確性驗證,而 OpenLedger 則通過歸屬機制實現對推理過程的責任追蹤與可解釋性。
數據側協作路徑:OpenLedger vs. Sapien / FractionAI / Vana / Irys
Sapien 與 FractionAI 提供去中心化數據標註服務,Vana 與 Irys 聚焦數據主權與確權機制。OpenLedger 則通過 Datanets + PoA 模塊,實現高質量數據的使用追蹤與鏈上激勵分發。前者可作為數據供給上游,OpenLedger 則作為價值分配與調用中樞,三者在數據價值鏈上具備良好協同,而非競爭關係。
總結來看,OpenLedger 在當前 Crypto AI 生態中佔據「鏈上模型資產化與調用激勵」這一中間層位置,既可向上銜接訓練網絡與數據平台,也可向下服務 Agent 層與終端應用,是連接模型價值供給與落地調用的關鍵橋樑型協議。
八、結論 | 從數據到模型,AI 鏈的變現之路
OpenLedger 致力於打造 Web3 世界中的「模型即資產」基礎設施,通過構建鏈上部署、調用激勵、歸屬確權與智能體組合的完整閉環,首次將 AI 模型帶入真正可追溯、可變現、可協同的經濟系統中。其圍繞 Model Factory、OpenLoRA、PoA 和 Datanets 構建的技術體系,為開發者提供低門檻的訓練工具,為數據貢獻者保障收益歸屬,為應用方提供可組合的模型調用與分潤機制,全面激活 AI 價值鏈中長期被忽視的「數據」與「模型」兩端資源。
OpenLedger 更像 HuggingFace + Stripe + Infura 的在 Web3 世界的融合體,為 AI 模型提供託管、調用計費與鏈上可編排的 API 接口。隨着數據資產化、模型自治化、Agent 模塊化趨勢加速演進,OpenLedger 有望成為「Payable AI」模式下的重要中樞 AI 鏈。