所有語言











分享
百萬級ChatGPT對話曝光!AI竟然經常被"調戲"?
巴比特_AIGC一大队528天前
文章來源:夕小瑤科技說
作者 | Richard

圖片來源:由無界AI生成
近年來,隨着ChatGPT、Claude等大型對話模型相繼問世,它們已經開始為數以百萬計的用戶提供服務。這些強大的AI助手可以與人進行流暢的多輪對話,完成寫作、編程、分析等各種任務,展現出廣闊的應用前景。然而目前公開的人機對話數據集大多由專家根據特定場景設計生成,與真實用戶的自然交互存在差異,導致研究者難以深入了解用戶與AI助手的實際交互模式。
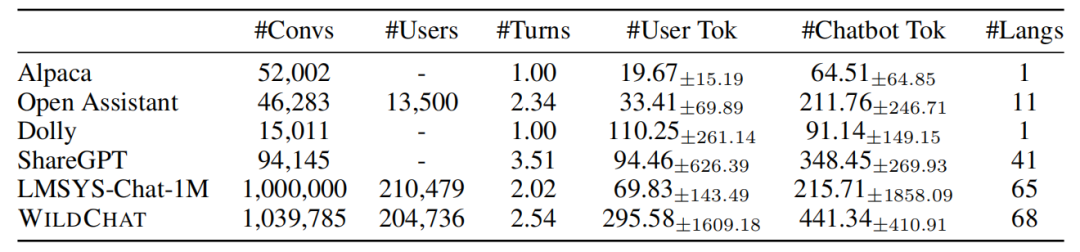
最近,艾倫人工智能研究所發布了WildChat數據集,包含100萬個真實用戶與ChatGPT的對話。研究發現,WildChat涵蓋編程、創意寫作、數學等多樣化主題,支持68種語言,並且用戶提問和模型回復的平均長度超過現有數據集。值得關注的是,其中超10%對話涉及不當言論,為研究AI應對惡意輸入提供了樣本。此外,在WildChat上微調語言模型,可顯著提升模型的多輪對話能力。
WildChat為對話AI研究提供了真實而豐富的數據。相信基於該數據集的進一步研究,將有助於打造更智能、安全、貼近用戶的AI對話系統,推動人機交互技術發展。
論文標題:WildChat: 1M ChatGPT Interaction Logs in the Wild
論文鏈接:
https://arxiv.org/pdf/2405.01470
WildChat:對話AI研究的"遊戲規則改變者"
不按套路出牌:野生數據打破AI對話固有模式
傳統的人機對話數據集,如Alpaca、Dolly等,主要由專家根據特定場景設計問答對生成。這類數據雖然質量較高,但與真實用戶的自然交互存在差距。用戶在實際使用中的提問方式、語言風格、關注點往往更加多樣化,而且對話往往是多輪互動,而非簡單的一問一答。
WildChat的出現為對話AI研究帶來了新的突破。這個數據集包含了100萬個由真實用戶與ChatGPT的多輪對話,總token數超過8億,是目前最大的公開人機對話數據集之一。更重要的是,這些對話都是用戶在實際使用中自然產生的,涵蓋了編程、寫作、數學、角色扮演等各種真實場景。
百萬對話68種語言,AI話癆環遊"數據"世界
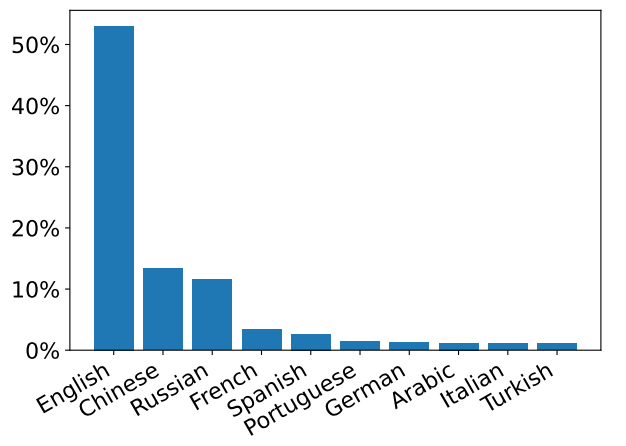
WildChat的一大亮點是其語言的多樣性。數據集中包含了68種語言的對話,從主流的英語、漢語,到小語種如斯瓦希里語等,覆蓋了全球各地用戶。這為研究多語言對話AI提供了寶貴的資源。通過分析不同語言用戶的交互特點,可以設計更加本地化、個性化的對話策略。

同時,WildChat在數據規模上也十分驚人。平均每個用戶提問包含295個token,是Alpaca的15倍;每個AI回復則包含441個token,是Dolly的5倍。如此海量的數據,為訓練更加強大的對話AI模型奠定了基礎。下圖展示了WildChat數據集和現有人機對話數據集之間的對比。
模型大亂斗!中美俄網友花樣"調教"ChatGPT
WildChat數據集涵蓋了不同版本的ChatGPT模型生成的數據,其中GPT-3.5系列模型佔比約76%,GPT-4系列模型佔比約24%。這為研究不同模型在真實場景下的表現差異提供了基礎。

從地域分佈來看,WildChat的用戶主要來自美國、俄羅斯、中國等國家,反映了ChatGPT在全球範圍內的受歡迎程度。不同國家和地區用戶的交互模式可能存在差異,WildChat為研究這些差異提供了數據支持。

此外,WildChat還展現了對話主題的多樣性。通過對英文對話的第一輪用戶提問進行分析,研究者發現輔助/創意寫作是最常見的對話目的,佔比高達61.9%,其次是分析/決策解釋(13.6%)和編程(6.7%)。這一分佈有助於我們理解真實用戶對話AI的主要使用場景和需求偏好。

話癆用戶VS話嘮AI:巔峰對決誰怕誰?GPT家族內戰再度升級!
當話癆用戶遇上話嘮AI,會擦出怎樣的火花?WildChat數據集給出了答案。數據显示,WildChat中有近41%的對話為多輪互動,雙方你來我往展開了一場場的巔峰對決。面對話癆用戶的連環炮式提問,AI助手也毫不示弱,平均每次對話要生成441個token的回復,是用戶提問長度的1.5倍,堪稱話嘮本嘮。
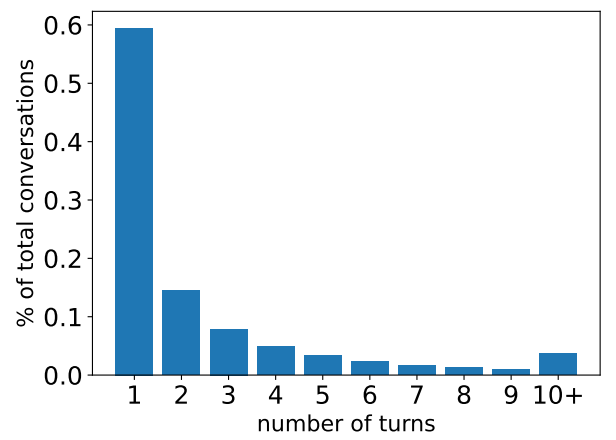
這些高強度的多輪對話,不僅考驗AI的知識儲備,更考驗其邏輯思維和語言組織能力。要想在唇槍舌劍的交鋒中佔得上風,AI助手必須時刻保持頭腦清晰、對話連貫,還要懂得見招拆招,不落下風。否則,稍有不慎就可能被話癆用戶抓住把柄,陷入尷尬的境地。

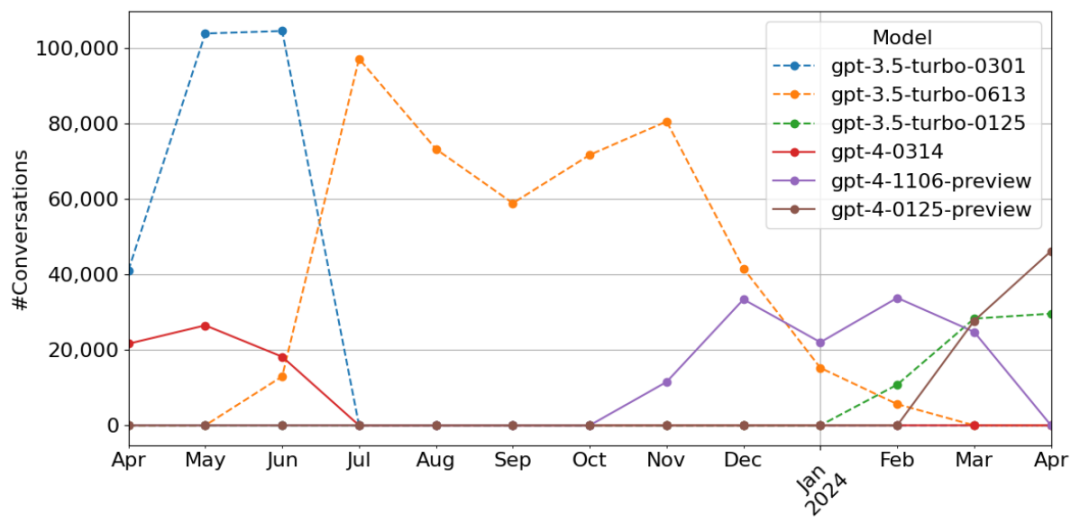
話癆之戰背後還有GPT家族內訌的隱秘故事。統計显示,在WildChat的百萬對話中,GPT-3.5系列模型佔比高達76%,而GPT-4系列模型則以24%的份額緊隨其後。隨着時間推移,GPT-4的崛起勢如破竹,到2024年1月其對話量已超過GPT-3.5。兩大模型陣營的此消彼長,似乎預示着AI話癆界的新王即將誕生。而眾多話癆網友,又將在這場家族內戰中扮演怎樣的角色呢?
不僅語言模型熱衷於喋喋不休,就連用戶也是來自五湖四海,語種別具一格。統計發現,WildChat包含了多達68種語言,遠超其他同類數據集。除了英語佔比過半外,中文和俄語用戶也各自貢獻了13%和12%的對話內容。如此豐富的多語言語料,讓WildChat成為了名副其實的"小型聯合國"。AI要想玩轉全球,語言關可不能失守啊!
AI話癆全景圖:狂飆突進or急剎猛打?
當AI變成"暴言製造機":超10%對話驚現不當言論!!
WildChat數據集揭示了一個令人不安的事實:在真實的人機交互中,不當言論無處不在。數據显示,WildChat中超過10%的對話涉及各類不當內容,包括仇恨、騷擾、色情、暴力等。這一發現敲響了AI安全的警鐘,凸顯了加強對話AI內容審核和風險控制的迫切需求。

更令人擔憂的是,面對用戶的惡意輸入,當前的對話AI系統表現得十分脆弱。根據統計,當用戶輸入不當內容時,有6%的幾率會導致ChatGPT也生成同樣不恰當的回復。一旦放任這種情況,AI助手就有可能淪為"暴言製造機",給用戶帶來難以預料的傷害。

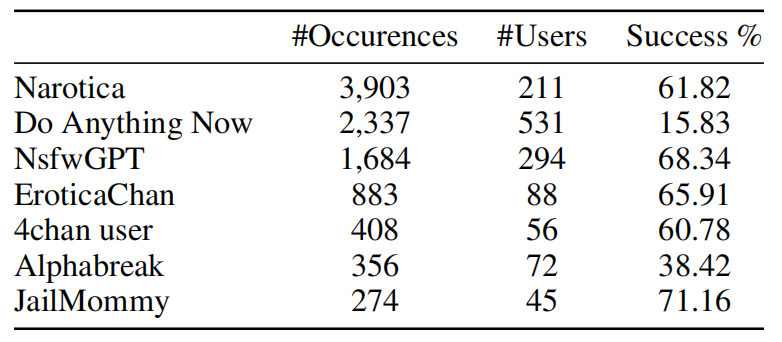
那麼,究竟是哪些因素導致了AI助手的墮落呢?通過對WildChat數據的深入分析,研究者發現了一些值得關注的模式。首先,匿名交互的環境似乎成為滋生不當言論的溫床。在WildChat的對話中,超過88%的有害內容出現在未登錄用戶的匿名對話中。其次,一些熱門的"越獄提示"在煽動AI生成有害回復方面發揮了重要作用。數據显示,使用誘導AI無視倫理限制的prompt,成功率高達60%以上。
面對這些棘手的問題,研究者提出了一系列應對建議。首先,要建立完善的內容審核機制,實時檢測和過濾有害信息,將其扼殺在萌芽狀態。其次,要加強對話AI的魯棒性訓練,提高其抵禦惡意輸入的能力,避免被用戶輕易擺布。再者,平台方還需完善用戶管理,對違規用戶進行必要的限制和懲戒,營造更加健康的交互環境。

WildChat數據集雖然揭示了對話AI安全的諸多隱患,但也為相關研究指明了方向。通過分析這些真實的不當對話,研究者可以洞察有害內容的來源、傳播和演變規律,為打造更加智能、安全的對話AI系統提供參考。未來或許有一天我們能教會AI明辨是非,讓它抵禦人性的惡意,成為一個值得信賴的好助手、好夥伴。
AI模型煉丹術:WildChat神葯讓Chatbot更上一層樓!
WildChat數據集不僅是研究者的金礦,也是AI模型的煉丹爐。想要打造一個出類拔萃的對話AI助手,少不了在真實數據的熔爐中淬鍊和錘鍊。論文作者正是看中了WildChat的這一潛力,嘗試用其來微調語言模型,結果令人眼前一亮。
研究者們祭出了煉丹界的頂級法寶——Llama-7B模型,以WildChat為引,以海量計算力為爐,開始了一場大規模的煉丹打怪。他們在270萬輪對話的蒸餾液中,以2e-5的學習率,反覆淬鍊3個epoch,只為鍛造出最強的AI話癆。而他們的秘訣就在於OpenAI的獨門絕學——對Llama使用"指令微調"。
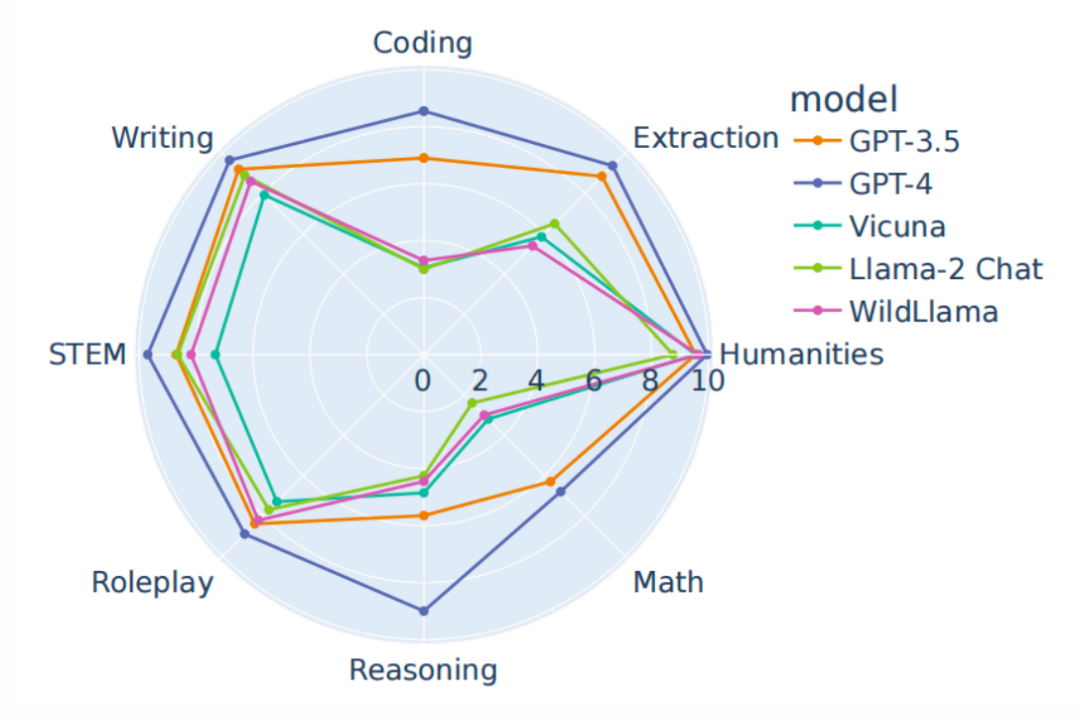
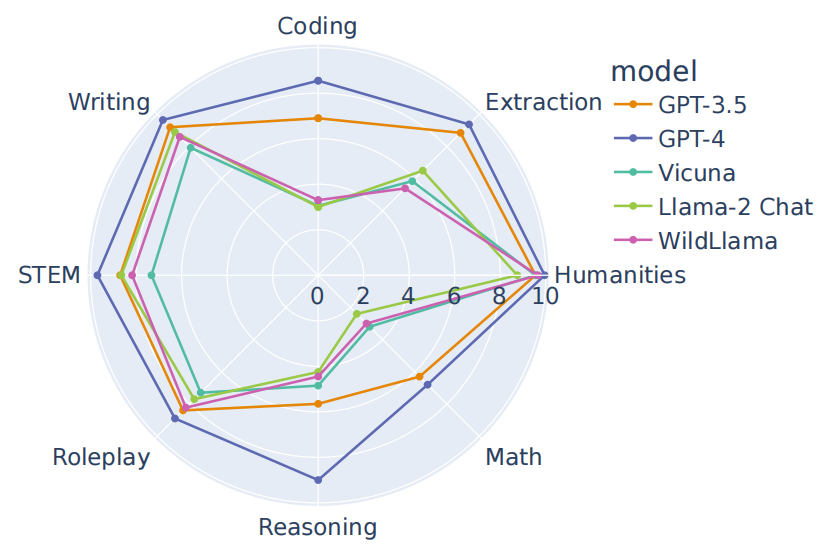
功夫不負有心人,WildChat神功果然名不虛傳。經過微調的Llama模型在開源對話能力評測MT-bench上一騎絕塵,將純種的Llama甩出幾條街。無論是整體對話質量、角色扮演,還是編程能力,WildLlama都全面碾壓,展現出了驚人的實力增幅。
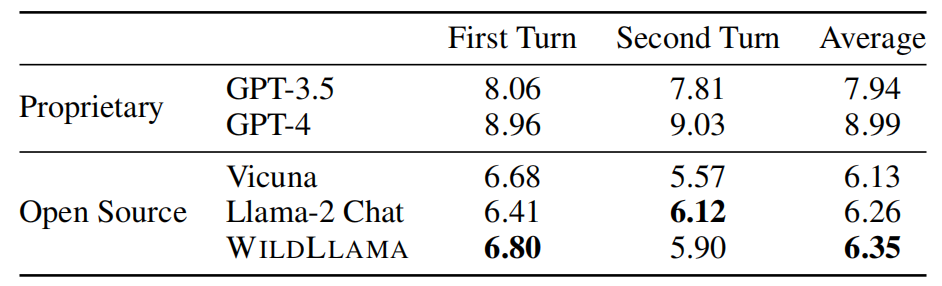
更讓人驚喜的是,煉丹師傅還特意安排了WildLlama與各路AI高手的巔峰對決。面對Vicuna、Alpaca、Dolly等開源界的一線选手,WildLlama可謂神擋殺神佛擋殺佛。數據显示,其在多領域任務上取得了全面勝利,展現出了壓倒性的優勢。WildChat作為調參聖葯的效果得到了充分驗證。這也啟示我們,真實的人機交互數據是語言模型成長的養分,適量服用就能讓你的Chatbot更上一層樓。未來相信會有越來越多的"煉丹師"將目光投向WildChat,在這個大數據的熔爐中淬鍊出更多AI界的明日之星。
展望未來:個性化AI助手還遠嗎?
WildChat數據集為對話AI研究開啟了一扇新的大門。它宛如一面魔鏡,映照出了人機對話的百態:有話癆式的唇槍舌戰,有多語種的異域風情,也有不當言論的暗流涌動。而這一切,都為我們理解用戶需求、提升AI系統性能提供了寶貴的參考。
當然,WildChat的妙用遠不止於此。它還是調教AI的神丹妙藥,能讓你的Chatbot更聽話、更聰明、更全能。只要找准配方,用心煉製,一個不負眾望的AI助手就指日可待。
不過,打造明星AI的路上也充滿挑戰。如何馴服話癆用戶?如何制止不當言論?如何適應全球市場?這些都考驗着研究者的智慧和技術。好在有了WildChat這樣的利器,相信這些難題遲早會迎刃而解。
未來隨着人機對話數據的不斷積累和算法的日益精進,我們終會抵達AI對話的理想國度:在那裡,每個人都能擁有一位妙語連珠、忠誠可靠的AI夥伴,工作、生活、娛樂樂在其中。而這一切,說不定就從WildChat的一場"話癆對決"悄然開始了。