所有語言











分享
Open-Sora全面開源升級:支持16s視頻生成和720p分辨率
巴比特_绘声绘影538天前
文章來源:機器之心

圖片來源:由無界AI生成
Open-Sora 在開源社區悄悄更新了,現在單鏡頭支持長達16秒的視頻生成,分辨率最高可達720p,並且可以處理任何寬高比的文本到圖像、文本到視頻、圖像到視頻、視頻到視頻和無限長視頻的生成需求。我們來試試效果。
生成個橫屏聖誕雪景,發b站

再生成個豎屏,發抖音

還能生成單鏡頭16秒的長視頻,這下人人都能過把編劇癮了

怎麼玩?指路
GitHub:https://github.com/hpcaitech/Open-Sora
更酷的是,Open-Sora 依舊全部開源,包含最新的模型架構、最新的模型權重、多時間/分辨率/長寬比/幀率的訓練流程、數據收集和預處理的完整流程、所有的訓練細節、demo示例和詳盡的上手教程。
Open-Sora 技術報告全面解讀
最新功能概覽
作者團隊在GitHub上正式發布了Open-Sora 技術報告[1],根據筆者的了解,本次更新主要包括以下幾項關鍵特性:
- 支持長視頻生成;
- 視頻生成分辨率最高可達720p;
- 單模型支持任何寬高比,不同分辨率和時長的文本到圖像、文本到視頻、圖像到視頻、視頻到視頻和無限長視頻的生成需求;
- 提出了更穩定的模型架構設計,支持多時間/分辨率/長寬比/幀率訓練;
- 開源了最新的自動數據處理全流程。
時空擴散模型ST-DiT-2
作者團隊表示,他們對Open-Sora 1.0中的STDiT架構進行了關鍵性改進,旨在提高模型的訓練穩定性和整體性能。針對當前的序列預測任務,團隊採納了大型語言模型(LLM)的最佳實踐,將時序注意力中的正弦波位置編碼(sinusoidal positional encoding)替換為更加高效的旋轉位置編碼(RoPE embedding)。此外,為了增強訓練的穩定性,他們參考SD3模型架構,進一步引入了QK歸一化技術,以增強半精度訓練的穩定性。為了支持多分辨率、不同長寬比和幀率的訓練需求,作者團隊提出的ST-DiT-2架構能夠自動縮放位置編碼,並處理不同大小尺寸的輸入。
多階段訓練
根據Open-Sora 技術報告指出,Open-Sora 採用了一種多階段訓練方法,每個階段都會基於前一個階段的權重繼續訓練。相較於單一階段訓練,這種多階段訓練通過分步驟引入數據,更高效地實現了高質量視頻生成的目標。
初始階段大部分視頻採用144p分辨率,同時與圖片和 240p,480p 的視頻進行混訓,訓練持續約1周,總步長81k。第二階段將大部分視頻數據分辨率提升至240p和480p,訓練時長為1天,步長達到22k。第三階段進一步增強至480p和720p,訓練時長為1天,完成了4k步長的訓練。整個多階段訓練流程在約9天內完成,與Open-Sora1.0相比,在多個維度提升了視頻生成的質量。
統一的圖生視頻/視頻生視頻框架
作者團隊表示,基於Transformer的特性,可以輕鬆擴展 DiT 架構以支持圖像到圖像以及視頻到視頻的任務。他們提出了一種掩碼策略來支持圖像和視頻的條件化處理。通過設置不同的掩碼,可以支持各種生成任務,包括:圖生視頻,循環視頻,視頻延展,視頻自回歸生成,視頻銜接,視頻編輯,插幀等。
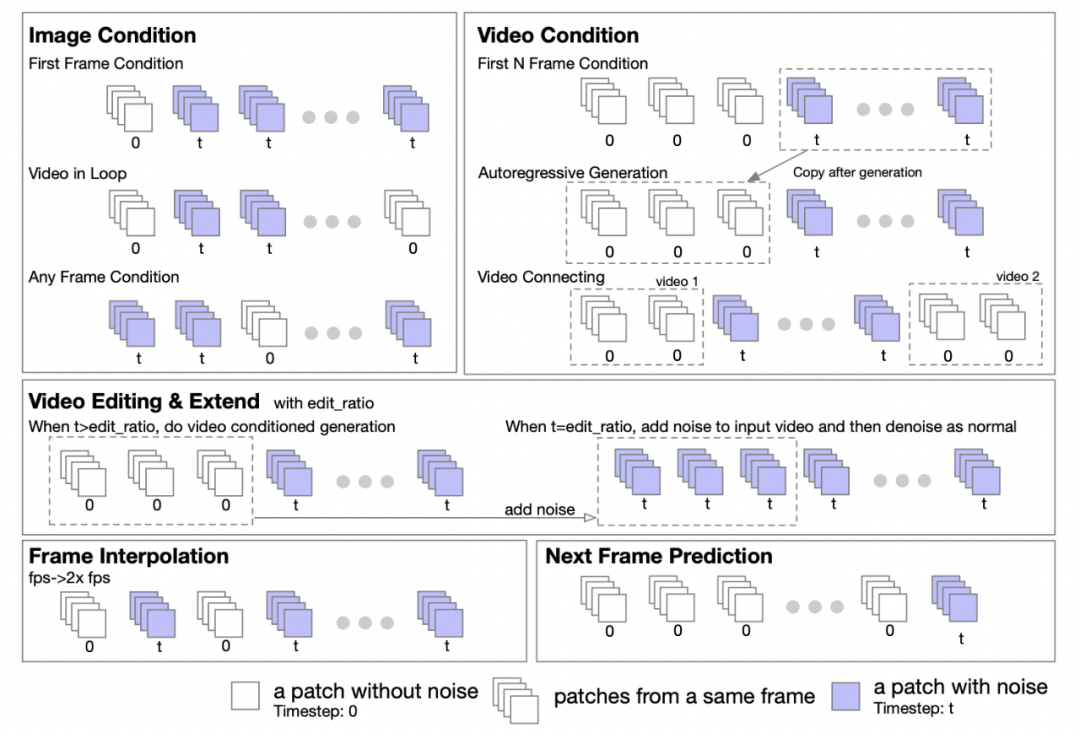
支持圖像和視頻條件化處理的掩碼策略
作者團隊表示,受到UL2[2]方法的啟發,他們在模型訓練階段引入了一種隨機掩碼策略。具體而言,在訓練過程中以隨機方式選擇並取消掩碼的幀,包括但不限於取消掩碼第一幀、前k幀、后k幀、任意k幀等。作者還向我們透露,基於Open-Sora 1.0的實驗,應用50%的概率應用掩碼策略時,只需少量步數模型能夠更好地學會處理圖像條件化。在Open-Sora 最新版本中,他們採用了從頭開始使用掩碼策略進行預訓練的方法。
此外,作者團隊還貼心地為推理階段提供了掩碼策略配置的詳細指南,五個数字的元組形式在定義掩碼策略時提供了極大的靈活性和控制力。
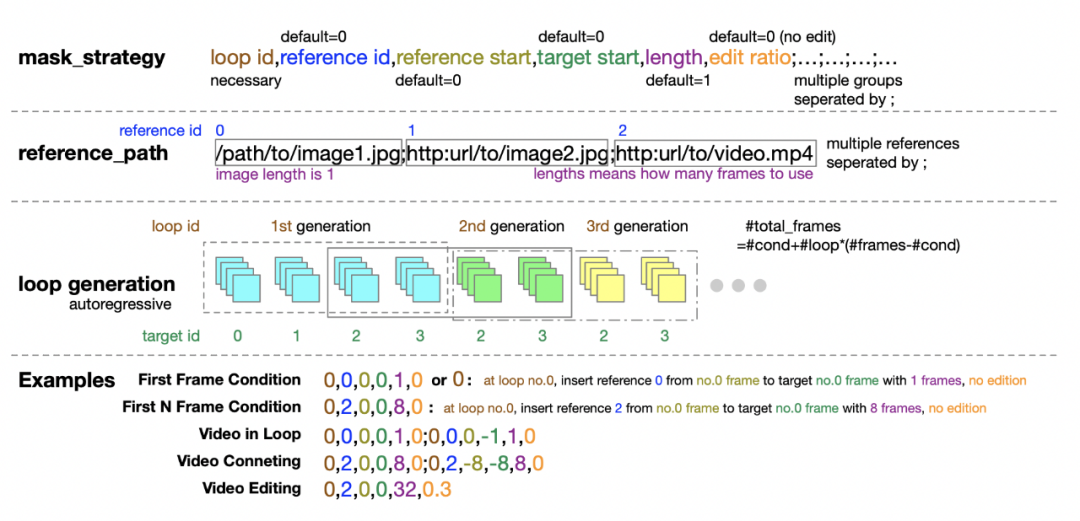
掩碼策略配置說明
支持多時間/分辨率/長寬比/幀率訓練
OpenAI Sora的技術報告[3]指出,使用原始視頻的分辨率、長寬比和長度進行訓練可以增加採樣靈活性,改善幀和構圖。對此,作者團隊提出了分桶的策略。
具體怎麼實現呢?通過深入閱讀作者發布的技術報告,我們了解到,所謂的桶,是(分辨率,幀數,長寬比)的三元組。團隊為不同分辨率的視頻預定義了一系列寬高比,以覆蓋大多數常見的視頻寬高比類型。在每個訓練周期epoch開始之前,他們會對數據集進行重新洗牌,並將樣本根據其特徵分配到相應的桶中。具體來說,他們會將每個樣本放入一個分辨率和幀長度均小於或等於該視頻特性的桶中。
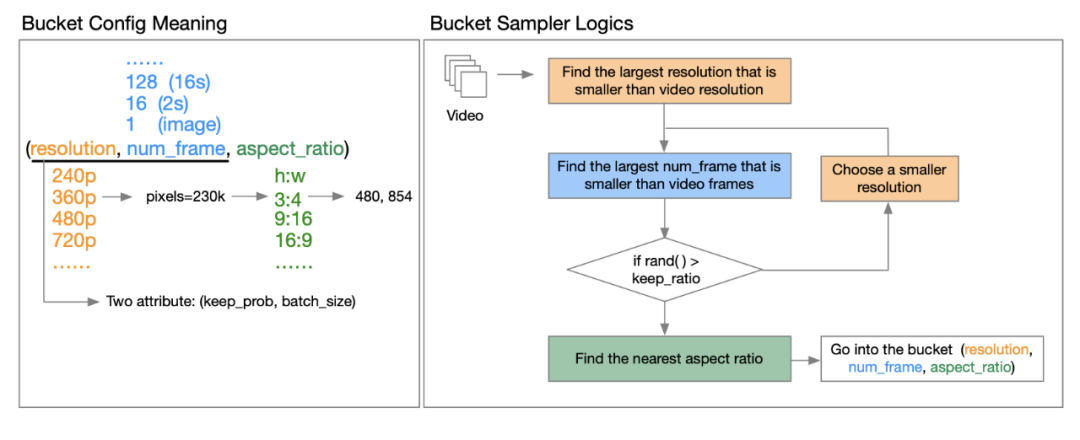
Open-Sora 分桶策略
作者團隊進一步透露,為了降低計算資源的要求,他們為每個keep_prob和batch_size引入兩個屬性(分辨率,幀數),以減少計算成本並實現多階段訓練。這樣,他們可以控制不同桶中的樣本數量,並通過為每個桶搜索良好的批大小來平衡GPU負載。作者在技術報告中對此進行了詳盡的闡述,感興趣的小夥伴可以閱讀作者在GitHub上發布的技術報告來獲取更多的信息:https://github.com/hpcaitech/Open-Sora
數據收集和預處理流程
作者團隊甚至對數據收集與處理環節也提供了詳盡的指南。根據作者在技術報告中的闡述,在Open-Sora 1.0的開發過程中,他們意識到數據的數量和質量對於培育一個高效能模型極為關鍵,因此他們致力於擴充和優化數據集。他們建立了一個自動化的數據處理流程,該流程遵循奇異值分解(SVD)原則,涵蓋了場景分割、字幕處理、多樣化評分與篩選,以及數據集的管理系統和規範。同樣,他們也將數據處理的相關腳本無私地分享至開源社區。對此感興趣的開發者現在可以利用這些資源,結合技術報告和代碼,來高效地處理和優化自己的數據集。
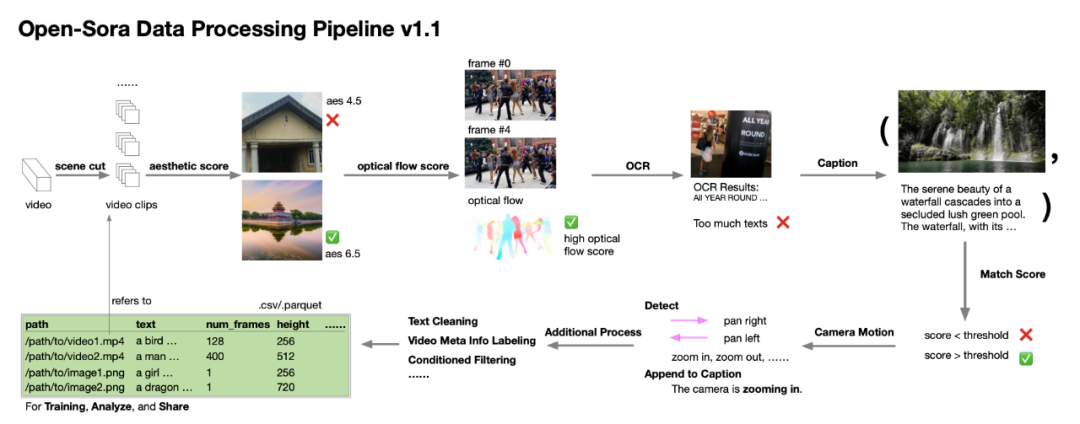
Open-Sora 數據處理流程
Open-Sora 性能全方位評測
視頻生成效果展示
Open-Sora 最令人矚目的亮點在於,它能夠將你腦中的景象,通過文字描述的方式,捕捉並轉化為動人的動態視頻。那些在思維中一閃而過的畫面和想象,現在得以被永久地記錄下來,並與他人分享。在這裏,筆者嘗試了幾種不同的prompt,作為拋磚引玉。
比如,筆者嘗試生成了一個在冬季森林里遊覽的視頻。雪剛下不久,松樹上掛滿了皚皚白雪,暗色的松針和潔白的雪花錯落有致,層次分明。

又或者,在一個靜謐夜晚中,你身處像無數童話里描繪過黑暗的森林,幽深的湖水在漫天璀璨的星河的照耀下波光粼粼。

在空中俯瞰繁華島嶼的夜景則更是美麗,溫暖的黃色燈光和絲帶一樣的藍色海水讓人一下子就被拉入度假的悠閑時光里。

城市裡的車水馬龍,深夜依然亮着燈的高樓大廈和街邊小店,又有另一番風味。

除了風景之外,Open-Sora 還能還原各種自然生物。無論是紅艷艷的小花,

還是慢悠悠扭頭的變色龍, Open-Sora 都能生成較為真實的視頻。

筆者還嘗試了多種 prompt 測試,還提供了許多生成的視頻供大家參考,包括不同內容,不同分辨率,不同長寬比,不同時長。






筆者還發現,僅需一個簡潔的指令,Open-Sora便能生成多分辨率的視頻短片,徹底打破創作限制。

分辨率:16*240p

分辨率:32*240p

分辨率:64*360p

分辨率:480*854p
我們還可以餵給Open-Sora一張靜態圖片讓它生成短片




Open-Sora 還可以將兩個靜態圖巧妙地連接起來,輕觸下方視頻,將帶您體驗從下午至黃昏的光影變幻,每一幀都是時間的詩篇。

再比如說我們要對原有視頻進行編輯,僅需一個簡單的指令,原本明媚的森林便迎來了一場鵝毛大雪。


我們也能讓Open-Sora 生成高清的圖片



值得注意的是,Open-Sora的模型權重已經完全免費公開在他們的開源社區上,不妨下載下來試一下。由於他們還支持視頻拼接功能,這意味着你完全有機會免費創作出一段帶有故事性的小短片,將你的創意帶入現實。
權重下載地址:https://github.com/hpcaitech/Open-Sora
當前局限與未來計劃
儘管在復現類Sora文生視頻模型的工作方面取得了不錯的進展,但作者團隊也謙遜地指出,當前生成的視頻在多個方面仍有待改進:包括生成過程中的噪聲問題、時間一致性的缺失、人物生成質量不佳以及美學評分較低。對於這些挑戰,作者團隊表示,他們將在下一版本的開發中優先解決,以期望達到更高的視頻生成標準,感興趣的朋友不妨持續關注一下。我們期待Open-Sora社區帶給我們的下一次驚喜。
開源地址:https://github.com/hpcaitech/Open-Sora
參考文獻:
[1] https://github.com/hpcaitech/Open-Sora/blob/main/docs/report_02.md
[2] Tay, Yi, et al. "Ul2: Unifying language learning paradigms." arXiv preprint arXiv:2205.05131 (2022).
[3] https://openai.com/research/video-generation-models-as-world-simulators