所有語言











分享
重磅!Llama-3,最強開源大模型正式發布!
巴比特_AI信息快递540天前
文章來源:AIGC開放社區

4月19日,全球科技、社交巨頭Meta在官網,正式發布了開源大模型——Llama-3。
據悉,Llama-3共有80億、700億兩種參數,分為基礎預訓練和指令微調兩種模型(還有一個超4000億參數正在訓練中)。
與Llama-2相比,Llama-3使用了15T tokens的訓練數據,在推理、數學、代碼生成、指令跟蹤等能力獲得大幅度提升。
此外,Llama-3還使用了分組查詢注意力、掩碼等創新技術,幫助開發者以最低的能耗獲取絕佳的性能。很快,Meta就會發布Llama-3的論文。
開源地址:
https://huggingface.co/collections/meta-llama/meta-llama-3-66214712577ca38149ebb2b6
Github地址:
https://github.com/meta-llama/llama3/
英偉達在線體驗Llama-3:
https://www.nvidia.com/en-us/ai/#referrer=ai-subdomain

「AIGC開放社區」曾在今年3月13日,根據Llama-3的硬件設施和訓練速度,預測其將於4月末發布果然被說中了。
但首發的Llama-3雖然在性能上獲得大幅度提升,功能上卻沒有帶來太多的驚喜,例如,將類Sora的視頻,或者Suno那樣的音頻功能內置在模型中,通過文本直接生成。
其實,Meta已經發布了很多音頻、視頻還有圖像的產品和研究論文,想整合它們估計只是時間問題。我們就期待一下Llama-3可以在未來幾個月,帶來更多的亮眼功能吧。
Llama-3簡單介紹
本次Llama-3的介紹與前兩個版本差不多,大量的測試數據和格式化介紹。但Meta特意提到Llama-3使用了掩碼和分組查詢注意力這兩項技術。
目前,大模型領域最流行的Transformer架構的核心功能是自我注意力機制,這是一種用於處理序列數據的技術,可對輸入序列中的每個元素進行加權聚合,以捕獲元素之間的重要關係。
但在使用自我注意力機制時,為了確保模型不會跨越文檔邊界,通常會與掩碼技術一起使用。在自我注意力中,掩碼被應用於注意力權重矩陣,用於指示哪些位置的信息是有效的,哪些位置應該被忽略。
通常當處理文檔邊界時,可以使用兩種類型的掩碼來確保自我注意力不會跨越邊界:1)填充掩碼,當輸入序列的長度不一致時,通常會對較短的序列進行填充,使其與最長序列的長度相等。
填充掩碼用於標記填充的位置,將填充的部分掩蓋,使模型在自我注意力計算中忽略這些位置。
2)未來掩碼,在序列生成任務中,為了避免模型在生成當前位置的輸出時依賴後續位置的信息,可以使用未來掩碼。
未來掩碼將當前位置之後的位置都掩蓋起來,使得自我注意力只能關注當前或之前的位置。
此外,在Transformer自注意力機制中,每個查詢都會計算與所有鍵的相似度並進行加權聚合。
而在分組查詢注意力中,將查詢和鍵分組,並將注意力計算限制在每個查詢與其對應組的鍵之間,從而減少了模型計算的複雜度。
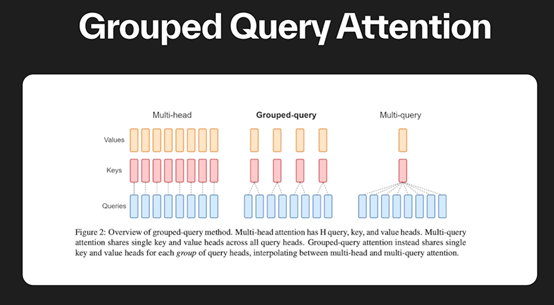
由於減少了計算複雜度,分組查詢注意力使得大模型更容易擴展到處理更長的序列或更大的批次大小。這對於處理大規模文本數據或需要高效計算的實時應用非常有益。
同時分組查詢注意力允許在每個查詢和其對應組的鍵之間進行關注的計算,從而控制了注意力的範圍。這有助於模型更準確地捕捉查詢和鍵之間的依賴關係,提高了表示能力。
Meta表示,Llama-3 還使用了一個 128K的詞彙表標記器,能更有效地編碼語言,在處理語言時也更加靈活。
訓練數據方面,lama 3 在超過 15T tokens的公開數據集上進行了預訓練。這個訓練數據集是 Llama 2 的7倍,包含的代碼數量也是 Llama 2 的4倍。
為了實現多語言能力,Llama 3 的預訓練數據集中有超過 5% 的高質量非英語數據,涵蓋 30 多種語言。
Llama-3測試數據
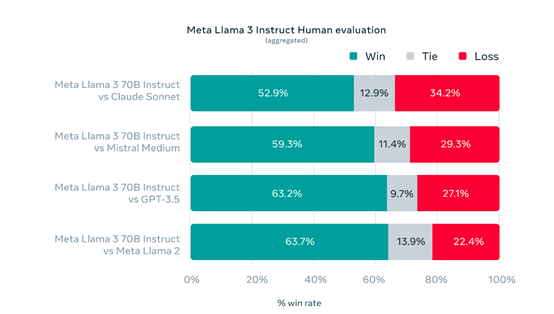
為了測試Llama-3的性能,Meta開發了一個全新的高質量人類評估數據集,有1,800個提示,涵蓋12個關鍵用例,包含,徵求建議,頭腦風暴,分類,封閉式問題回答,編碼,推理等。
測試結果显示,Llama-3 -700億參數的指令微調模型的性能,大幅度超過了Claude Sonnet、Mistral Medium和GPT-3.5。
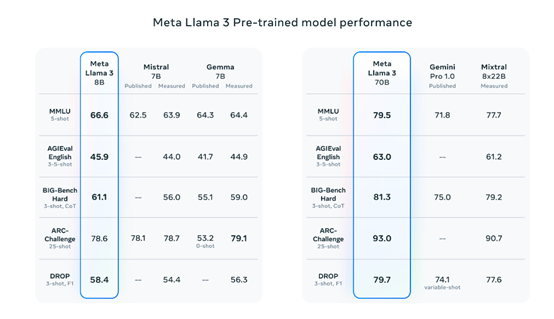
Meta還在MMLU、AGIEval、BIG、ARC等知名測試平台中,對Llama-3 -700億參數基礎預訓練模型進行了綜合測試,性能大幅度超過了Mistral 7B、Gemma 7B、Gemini Pro 1.0等知名開源模型。
本文素材來源Meta官網,如有侵權請聯繫刪除
END