所有語言











分享
8萬億訓練數據,性能超LLaMA-2,英偉達推出Nemotron-4 15B
巴比特_AIGC开放社区578天前
文章來源:AIGC開放社區

圖片來源:由無界AI生成
英偉達的研究人員推出了Nemotron-4 15B。這是一個擁有150億參數的大語言模型,並基於8萬億文本標註數據進行了預訓練。
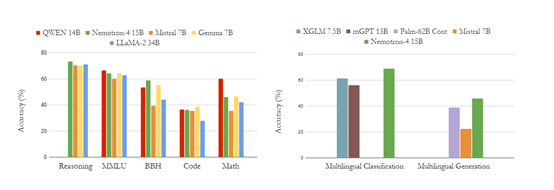
在數學、多語言分類和代碼等測試評估中,Nemotron-4 15B在7個領域中的4個超過了所有現役同類大小的開源模型,並且在其他領域中也表現出了優秀的性能。
技術報告地址:https://arxiv.org/abs/2402.16819
Nemotron-4 15B架構
Nemotron-4 15B使用了標準的Transformer架構,這是一種基於自注意力機制的深度神經網絡。

Transformer由多個相同的層組成,每個層都有多頭自注意力機制和前饋神經網絡。自注意力機制使模型能夠在輸入序列中捕捉到不同位置之間的依賴關係,以及輸入序列中各個位置之間的關聯性。前饋神經網絡則通過多層感知機,對每個位置的表示進行非線性變換。
解碼器:Nemotron-4 15B只使用了Transformer的部分解碼器。解碼器主要負責將輸入序列轉換為輸出序列,通過自注意力機制和前饋神經網絡對輸入序列進行處理。
注意力機制:在Nemotron-4 15B中,注意力機制被用於自注意力和全局注意力。自注意力用於學習輸入序列內部的依賴關係,而全局注意力用於學習輸入序列與輸出序列之間的對應關係。
通過注意力機制,模型能夠聚焦於輸入序列中與當前位置相關的信息,從而更好地理解上下文。

多頭注意力:在Nemotron-4 15B中,每個注意力機制都有多個注意力頭,每個頭都可以學習到不同的關注信息。
通過使用多頭注意力,模型能夠同時關注輸入序列中的不同方面,從而提高了模型的表達能力和泛化能力。
位置編碼:位置編碼是一種用於為輸入序列中的每個位置添加位置信息的技術。Nemotron-4 15B使用了旋轉位置編碼,使模型能夠在處理輸入序列時考慮到位置信息,從而更好地捕捉到序列中的順序關係。
Nemotron-4 15B數據與訓練流程
Nemotron-4 15B的訓練數據集由各種類型的數據組成,其中包括英語自然語言數據(70%)、多語言自然語言數據(15%)和源代碼數據(15%)。
為了使生成的內容更準確性,在構建預訓練語料庫時移除了重複數據,並對數據進行了高質量、精細過濾。

在訓練Nemotron-4 15B的過程中,研究人員利用了384個DGX H100節點,每個節點包含8個基於NVIDIA Hopper架構的H100 80GB SXM5 GPU。並採用了8路張量并行和數據并行(data parallelism)的組合,以及分佈式優化器進行分片。
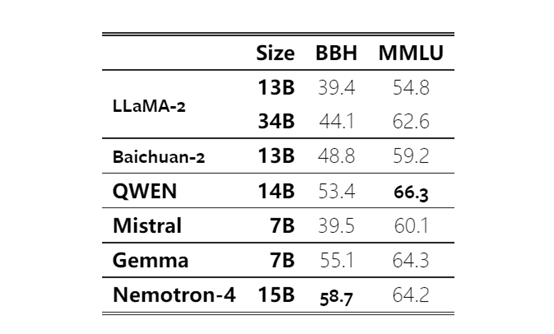
在英語、數學推理、多語言分類、代碼等測試任務中,Nemotron-4 15B在英語評估領域優於LLaMA-2 34B和Mistral 7B,並與QWEN 14B和Gemma 7B達到了相近的性能。
此外,Nemotron-4 15B在廣泛的代碼語言中表現出了更高的準確率,尤其在資源稀缺的編程語言上超過了Starcoder和Mistral 7B等模型。
本文素材來源Nemotron-4 15B技術報告,如有侵權請聯繫刪除