所有語言











分享
最長處理2小時,開源視頻字幕模型Video ReCap
巴比特_AIGC开放社区586天前
文章來源:AIGC開放社區

圖片來源:由無界AI生成
隨着抖音、快手等平台的火爆出圈,越來越多的用戶開始製作大量的短視頻內容。但對這些視頻進行有效的理解和分析仍面臨一些困難。尤其是視頻時長超過幾分鐘、甚至幾小時,傳統的視頻字幕生成技術往往無法滿足需求。
因此,北卡羅來納大學和Meta AI的研究人員開源了,視頻字幕模型Video ReCap。這是一種遞歸視頻字幕生成模型,能夠處理從1秒到2小時的視頻,並在多個層級上輸出視頻字幕。
此外,研究人員通過在Ego4D上增加8,267個手動收集的長視頻摘要,引入了一個層次化視頻字幕數據集Ego4D-HCap,並使用該數據集對Video ReCap進行了綜合評估。
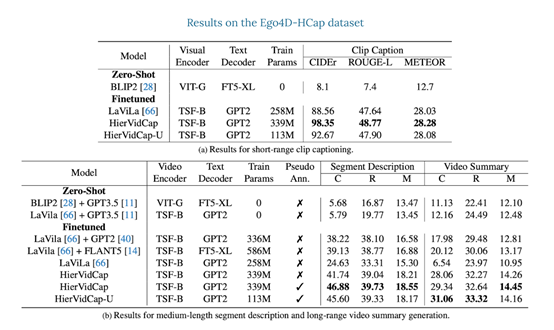
結果显示,Video ReCap在短視頻片段字幕、中等長度段描述和長視頻摘要的測試指標均明顯超過多個強大基準模型。通過該模型生成的分層視頻字幕,也能顯著提升基於EgoSchema數據集的長視頻問答效果。
開源地址:https://github.com/md-mohaiminul/VideoRecap?tab=readme-ov-file
論文地址:https://arxiv.org/abs/2402.13250

Video ReCap模型介紹
Video ReCap的核心技術是使用了遞歸視頻語言架構,主要通過遞歸處理機制,使模型能夠在不同的時間長度和抽象層級上理解視頻,從而生成精確且層次豐富的視頻描述字幕。主要由3大模塊組成。
1)視頻編碼器:Video ReCap使用了一個預訓練的視頻編碼器,從長視頻中提取特徵。對於短視頻片段,編碼器則輸出密集的時空特徵。
這允許模型捕獲細粒度的詳細信息,對於更高層級的字幕,使用全局特徵(如CLS特徵),以降低計算成本並捕獲長視頻輸入的全局屬性。
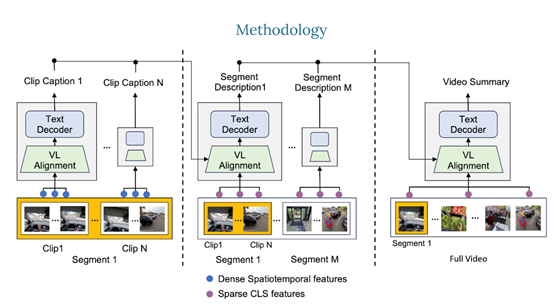
2)視頻-語言對齊:該模塊可以將視頻和文本特徵映射到聯合特徵空間,以便遞歸文本解碼器可以聯合處理兩者。
具體來說,使用了一個預訓練的語言模型,通過在每個轉換器塊內注入可訓練的交叉注意力層,從視頻特徵中學習固定數量的視頻嵌入。
然後,從屬於特定分層的字幕中學習文本嵌入。最後,連接視頻和文本嵌入以獲得聯合嵌入,並交給後續的遞歸文本解碼器使用。
3)遞歸文本解碼器:該模塊主要用於處理短、中、長三種視頻的字幕,所以,採用了一種分層的生成策略。首先,使用從短視頻剪輯中提取的特徵生成短剪輯級別的字幕。這些短剪輯級別的字幕描述了視頻中的原子動作和低級視覺元素,例如,對象、場景和原子動作等。

然後,使用稀疏採樣的視頻特徵和上一層級別生成的字幕作為輸入,生成當前層級別的視頻字幕。這種遞歸設計可以有效地利用不同視頻層次之間的協同作用,能高效地生成最多2小時的長視頻字幕。
Video ReCap實驗數據
為了評估Video ReCap模型,研究人員推出了一個新的分層視頻字幕數據集Ego4D-HCap。該數據集是基於目前最大的公開第一人稱視頻數據集之一Ego4D。
Ego4D-HCap主要包含三個層次的字幕:短剪輯字幕、幾分鐘長的段描述和長段視頻摘要,用於驗證分層視頻字幕任務的有效性。
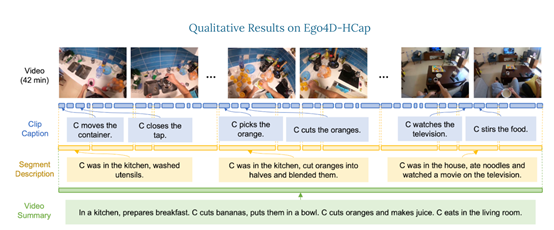
結果显示,在所有三個時間層級,Video ReCap模型都大幅度優於之前的強大的視頻字幕基準模型。此外,還發現遞歸架構對於生成段描述和視頻摘要非常重要。
例如,不帶遞歸輸入的模型在段描述生成方面CIDEr性能下降1.57%,而在長時間視頻摘要生成方面下降了2.42%。
研究人員還在最近推出的長序視頻問答基準EgoSchema上驗證了該模型。結果显示,Video ReCap生成的分層視頻字幕可以將文本問答模型的性能提高4.2%,並以50.23%的整體準確率刷新了記錄,比之前的最佳方法提高了18.13%。