所有語言











分享
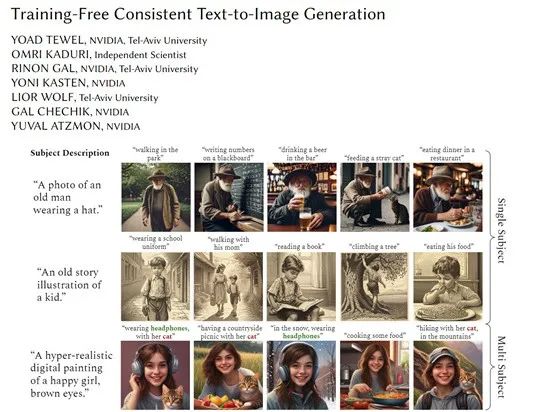
英偉達推出免訓練,可生成連貫圖片的文生圖模型
巴比特_AIGC开放社区592天前
文章來源:AIGC開放社區

圖片來源:由無界AI生成
目前,多數文生圖模型皆使用的是隨機採樣模式,使得每次生成的圖像效果皆不同,在生成連貫的圖像方面非常差。
例如,想通過AI生成一套圖像連環畫,即便使用同類的提示詞也很難實現。雖然DALL·E 3和Midjourney可以對圖像實現連貫的生成控制,但這兩個產品都是閉源的。
因此,英偉達和特拉維夫大學的研究人員開發了免訓練一致性連貫文生圖模型——ConsiStory。(即將開源)
論文地址:https://arxiv.org/abs/2402.03286
目前,文生圖模型在生成內容一致性方面比較差的原因主要有兩個:1)無法識別和定位圖像中的共同主體,文生圖像模型沒有內置的對象檢測或分割模塊,很難自動識別不同圖像中的相同主體;
2)無法在不同圖像中保持主體的視覺一致性,即使定位到主體,也很難使不同步驟中獨立生成的主體在細節上保持高度相似。
主流解決這兩種難題的方法是,基於個性化和編碼器的優化方法。但這兩類方法都需要額外的訓練流程,例如,針對特定主體微調模型參數,或使用目標圖像訓練編碼器作為條件。
即便使用了這種優化方法,訓練周期較長難以擴展到多個主體,且容易與原始模型分佈偏離。
而ConsiStory提出了一種全新的方法,通過共享和調整模型內部表示,可以在無需任何訓練或調優的情況下實現主體的一致性。
值得一提的是,ConsiStory可以作為一種插件,幫助其他擴散模型提升文生圖的一致性和連貫性。
主體驅動自注意力(SDSA)
SDSA是ConsiStory的核心模塊之一,可以在生成的圖像批次中共享主體相關的視覺信息,使不同圖像中的主體保持一致的外觀。
SDSA主要擴大了擴散模型中自注意力層,允許一個圖像中的“提示詞”不僅可以關注自己圖像的輸出結果,還可以關注批次中其他圖像的主體區域的輸出結果。
這樣主體的視覺特徵就可以在整個批次中共享,不同圖像中的主體互相"對齊"。
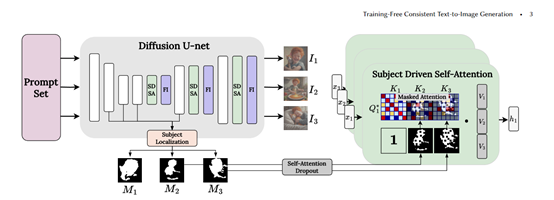
為了防止背景區域之間的敏感信息泄露,該模塊使用主體分割蒙版來進行遮蔽——每個圖像只能關注批次中其他圖像主體區域的輸出結果。

主體蒙版是通過擴散模型本身的交叉注意力特徵自動提取。
特徵注入
為了進一步增強主體不同圖像之間細節層面的一致性,“特徵注入”基於擴散特徵空間建立的密集對應圖,可以在圖像之間共享自注意力輸出特徵。
同時圖像中一些相似的優化地方之間共享自注意力特徵,這可以有效確保主體相關的紋理、顏色等細節特徵在整個批次中互相"對齊"。
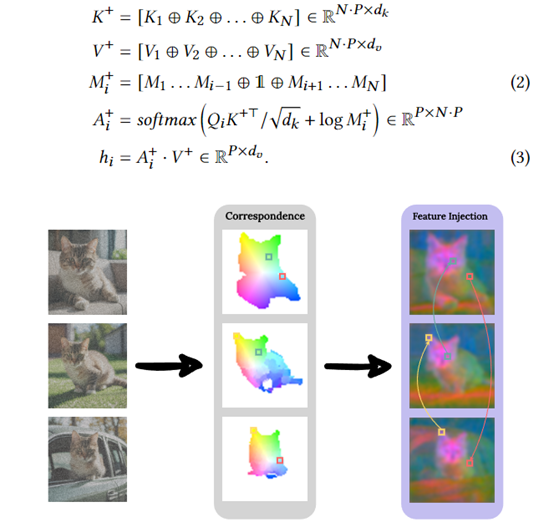
特徵注入也使用主體蒙版進行遮蔽,只在主體區域執行特徵共享。同時還設置相似度閾值,只在足夠相似的優化之間執行。
錨圖像和可重用主體
ConsiStory中的錨圖像提供了主題信息的參考功能,主要用於引導圖像生成過程,確保生成的圖像在主題上保持一致。
錨圖像可以是用戶提供的圖像,也可以是從其他來源獲取的相關圖像。在生成過程中,模型會參考錨圖像的特徵和結構,並盡可能地生成與一致性的圖像。

可重用主體是通過共享預訓練模型的內部激活,來實現主題一致性的方法。在圖像生成過程中,模型會利用預訓練模型的內部特徵表示來對生成的圖像進行對齊,而無需進一步對齊外部來源的圖像。

也就是說生成的圖像可以相互關注、共享特徵,這使得ConsiStory實現了0訓練成本,避免了傳統方法中需要針對每個主題進行訓練的難題。