所有語言











分享
文本生成高清、連貫視頻,谷歌推出時空擴散模型
巴比特_AIGC开放社区614天前
文章來源:AIGC開放社區

圖片來源:由無界AI生成
谷歌研究人員推出了創新性文本生成視頻模型——Lumiere。
與傳統模型不同的是,Lumiere採用了一種時空擴散(Space-time)U-Net架構,可以在單次推理中生成整個視頻的所有時間段,能明顯增強生成視頻的動作連貫性,並大幅度提升時間的一致性。
此外,Lumiere為了解決空間超分辨率級聯模塊,在整個視頻的內存需求過大的難題,使用了Multidiffusion方法,同時可以對生成的視頻質量、連貫性進行優化。
論文地址:https://arxiv.org/abs/2401.12945?ref=maginative.com
時空擴散U-Net架構
傳統的U-Net是一種常用於圖像分割任務的卷積神經網絡架構,其特點是具有對稱的編碼器-解碼器,能夠在多個層次上捕獲上下文信息,並且能夠精確地定位圖像中的對象。
而時空擴散U-Net是在時空維度上執行下採樣和上採樣操作,以便在緊湊的時空表示中生成視頻。
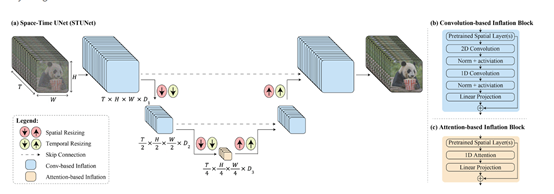
下採樣的目的是減小特徵圖的尺寸,同時增加特徵圖的通道數,以捕捉更豐富的特徵。
上採樣則是通過插值以及將特徵圖的尺寸恢復到原始輸入的大小,同時減少通道數,以生成更細節的輸出。
時空擴散U-Net的編碼器部分通過卷積和池化操作實現時空下採樣。卷積層用於提取特徵,並逐漸減小特徵圖的尺寸。

池化層則通過降採樣操作減小特徵圖的空間尺寸,同時保留重要的特徵信息。通過逐步堆疊這些下採樣模塊,編碼器可以逐漸提取出更高級別的抽象特徵。
因此,Lumiere在時空擴散U-Net架構幫助下,能夠一次生成80幀、16幀/秒(相當於5秒鐘)的視頻。並且與傳統方法相比,這種架構顯著增強了生成視頻運動的整體連貫性。
Multidiffusion優化方法
Multidiffusion核心技術是通過在時間窗口內進行空間超分辨率計算,並將結果整合為整個視頻段的全局連貫解決方案。
具體來說,Multidiffusion通過將視頻序列分割成多個時間窗口,每個時間窗口內進行空間超分辨率計算。

這樣做的好處是,在每個時間窗口內進行計算可以減少內存需求,因為每個時間窗口的大小相對較小。同時,這種分割的方式也使得計算更加高效,並且能夠更好地處理長視頻序列。

在每個時間窗口內,Multidiffusion方法使用已經生成的低分辨率視頻作為輸入,通過空間超分辨率級聯模塊生成高分辨率的視頻幀。
然後,通過引入擴散算法,將每個時間窗口的結果進行整合,形成整個視頻段的全局連貫解決方案。
這種整合過程考慮了時間窗口之間的關聯性,保證了視頻生成的連貫性和視覺一致性。