所有語言











分享
用大模型為病人提供醫療諮詢,谷歌推出AMIE模型
巴比特_AIGC开放社区618天前
文章來源:AIGC開放社區
醫生與患者之間的對話是確診病情、建立有效治療方案的關鍵所在。然而,現實中並不是所有人都能享受豐厚的醫療資源與醫生進行深度諮詢。
為了解決這一困境,谷歌的研究人員推出了專門用於醫療諮詢的大語言模型AMIE(Articulate Medical Intelligence Explorer)。
AMIE利用一種新穎的自我對話模擬環境,並結合自動反饋機制,以跨不同疾病狀況、專業領域和情境進行學習。
研究人員將AMIE與20名初級保健醫生在149個臨床案例中進行了評估,結果显示,AMIE在診斷準確率和交流水平等多個方面優於醫生。
論文地址:https://arxiv.org/abs/2401.05654

模擬對話環境
AMIE是基於谷歌的PaLM 2模型開發而成。為了使AMIE適應不同專科的醫生和病例,研究人員採用獨創的“模擬病人對話環境”進行訓練、微調。
可以根據網絡搜索結果自動生成各類病例數據,並由AMIE在裏面通過輪流學習與模擬病人對話,不斷改進自身能力。
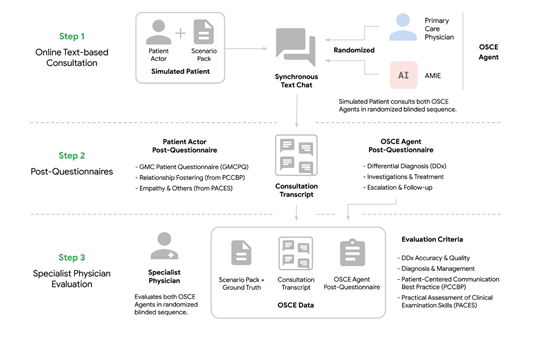
研發團隊從三個醫學數據庫中隨機選擇疾病情況,通過網絡搜索結果生成各類病例描述。隨後由AMIE分別扮演患者和醫生,在第三方評價機制監督下開展對話。
環境中設有患者模板代理、醫生模板代理以及評價模板代理三個角色。患者代理根據提供的病例描述進行回答;醫生代理提出問題分析病情;評價代理會根據對話質量給予反饋,幫助醫生代理逐步改進交流表現。
這套模擬環境可以自動生成大量規模醫療對話,彌補真實醫患交流數據匱乏的缺點,有效擴大了AMIE的學習範圍。
自我學習循環
研究人員設計了內外兩層循環機制,幫助AMIE實現自我學習。內循環中,AMIE會根據評價反饋不斷改進模擬對話效果;外循環中,收集模擬對話增強AMIE的後續訓練,建立自我細化循環。

隨着訓練不斷進行,AMIE的交互能力將日益提升;同時通過外循環學習,其醫療知識面也將不斷擴充,適應更多醫療情景。
鏈式推理策略
在真實的醫療對話過程中,AMIE採用了三步鏈式推理策略。第一步,根據對話歷史總結患者癥狀並提出初步診斷假設;第二步,在此基礎上定製回復方案和下一步問診目標,旨在進一步確定診斷;
第三步,檢查回復是否流暢準確,避免重重複問和錯誤信息,進行必要修訂、糾錯。研究人員認為,AMIE通過鏈式思考方式連續優化,相對於單次回復能實現更高的診斷準確率。
測試數據
為了評估AMIE的性能,研究人員設計並進行了一項帶有驗證的遠程客觀結構化臨床考試。通過文本界面,AMIE與經過驗證的模擬患者或初級保健醫生進行互動交流。
一共涉及149個臨床案例,20名初級保健醫生與AMIE進行比較,並由專業醫生和患者進行評估。

結果显示,根據專科醫生的評估,AMIE在診斷準確性和32個評估維度中有28個優於初級保健醫生;而根據患者的評估,AMIE在26個評估維度中有24個維度表現出更好的診斷結果。