所有語言











分享
用大模型訓練實體機器人,谷歌推出機器人代理模型
巴比特_AIGC开放社区620天前
原文來源:AIGC開放社區

圖片來源:由無界 AI生成
谷歌DeepMind的研究人員推出了一款,通過視覺語言模型進行場景理解,並使用大語言模型來發出指令控制實體機器人的模型——AutoRT。
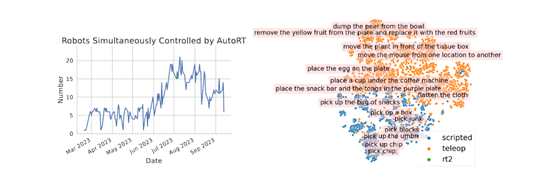
AutoRT可有效地推理自主權和安全性,並擴大實體機器人學習的數據收集規模。在實驗中,AutoRT指導超過20個實體機器人執行指令,並通過遠程操作和自主機器人策略收集了77,000個真實機器人操作的片段。
這充分說明,AutoRT收集的機器人操作數據更加多樣化,並且在大語言模型的幫助下AutoRT可以輕鬆實現與人類偏好相一致的機器人行為指令,該模型對於訓練實體機器人幫助巨大。
論文地址:https://auto-rt.github.io/static/pdf/AutoRT.pdf
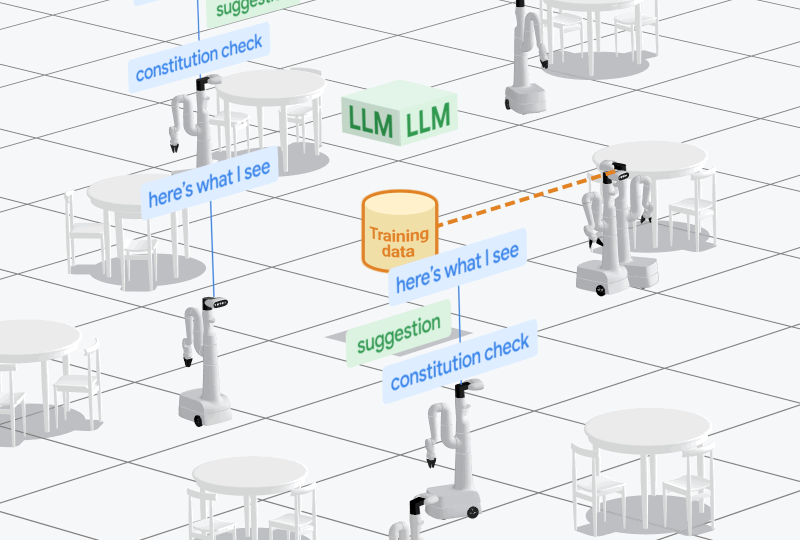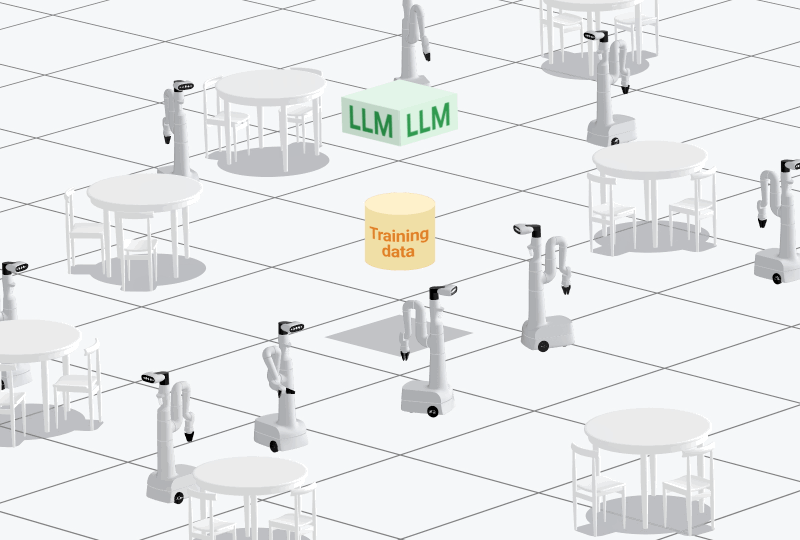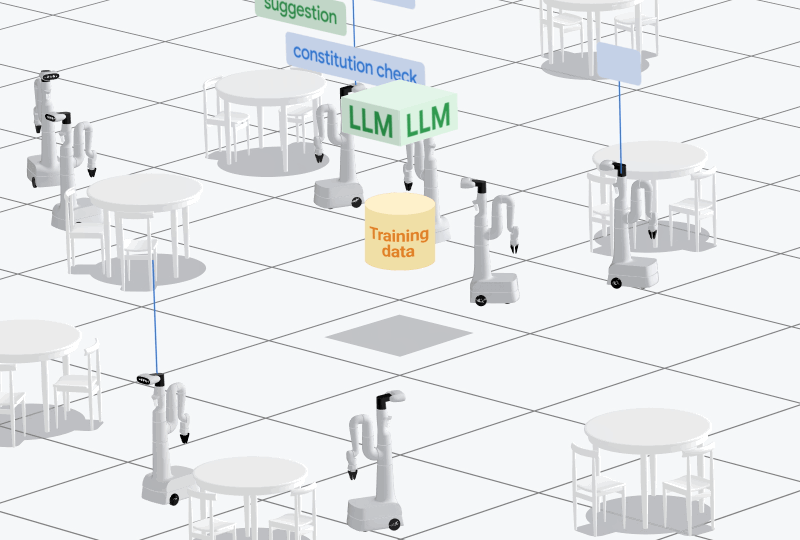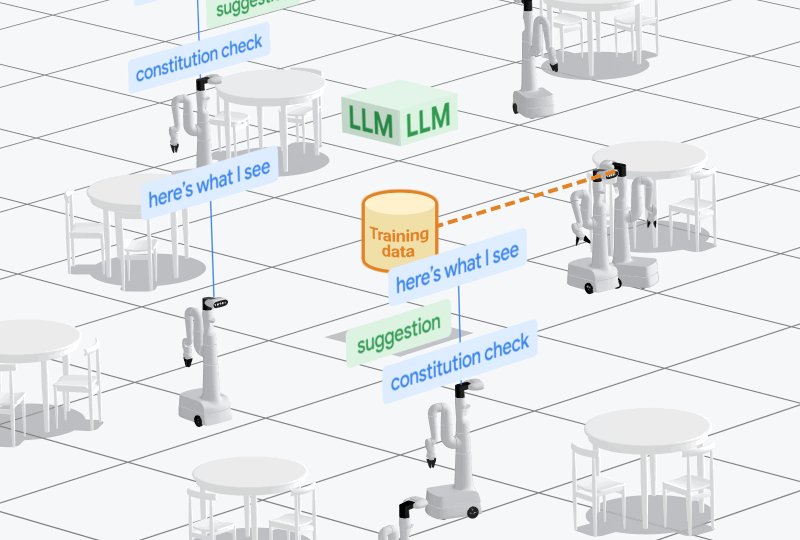
大語言模型是AutoRT的核心組建之一,充當機器人的指揮“大腦”,根據用戶的提示和環境條件為一個或多個機器人提供任務指令,主要包括環境探索、任務生成、自主行為和行為過濾四大模塊。
環境探索
負責讓機器人在環境中尋找適合操作的場景。該模塊使用了視覺語言模型構建環境地圖,識別並定位各個對象。
然後根據對象特徵採樣導航目標,引導機器人駛向潛在的操作場景。這使得AutoRT可以無需事先了解環境布局就進行部署。
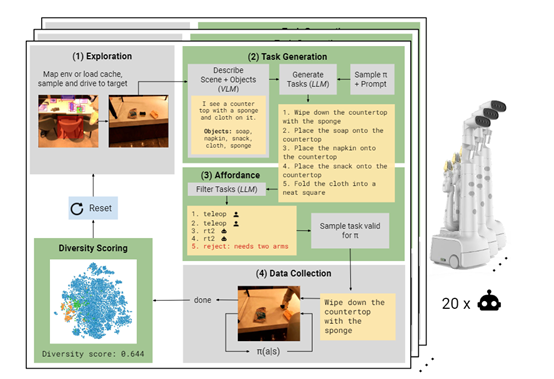
簡單來說,就是讓機器人自己在房間、辦公室等環境進行自行操作和觀察,到處看看有啥可以操作的東西。它會先把當前環境里的桌子、杯子這些物體定位好,明確具體的坐標,方便以後的動作指令操作。
任務指令生成
首先使用視覺語言模型描述當前場景和環境中的對象,然後將這些文字描述輸入大語言模型,生成機器人可以執行的一系列操作任務指令。
任務生成考慮不同的數據收集策略,為它們各自生成適配的任務列表。此外,任務生成過程中還內嵌了“機器人約束”,定義了機器人需要遵守的基本規則、安全規則和具體約束,確保任務的安全性和合理性。
自主執行
在任務執行階段,機器人根據生成的任務執行計劃來執行具體的操作。機器人可以根據需要執行自主策略,如通過路徑規劃和運動控制來移動和操作物體。
此外,機器人還可以通過與人類操作員進行通信來執行任務。在需要人類干預或指導的情況下,機器人可以向操作員發送請求或詢問,並根據操作員的指示進行相應的操作。
自主執行的目標是使機器人能夠在不同環境和任務下獨立運行,並從中獲取豐富的數據。
行為指令過濾
主要對任務生成的輸出進行再次篩選,移除不安全或不合理的任務。該模塊同樣基於大語言模型,將生成的任務及可選的數據收集策略作為輸入,同時輸出每個任務指令所匹配的策略或拒絕理由。

可以把這個模塊看成是一個自我反思的過程,大語言模型對自己生成的內容進行糾錯和修正,提升整體的安全性能。
通過以上4大模塊的協同工作,AutoRT能夠在真實世界的不同環境中快速收集大規模、多樣化的機器人數據。
相比於傳統的數據收集方法,AutoRT利用先進的視覺感知和語言模型技術,使機器人能夠在未知的情境下自主決策並執行任務,從而最大限度地提高數據收集的效率和安全性。
此外,AutoRT還支持與人類操作員的交互,使機器人能夠在需要時獲取人類的幫助和指導。