所有語言











分享
OpenAI「登月計劃」劍指超級AI!LeCun提出AGI之路七階段,打造世界模型是首位
巴比特_AGIing644天前
來源:新智元

圖片來源:由無界 AI生成
OpenAI「登月計劃」篤定了超級人工智能必定會到來,甚至近在眼前。而在LeCun看來,實現AGI還很遙遠,打造出世界模型僅是第一步。
通用AGI,或許近在咫尺。
OpenAI下一步「登月計劃」,就是實現人類期待已久的超級人工智能,而到達這一步的前提是——解決超級AI對齊問題。

就在前幾天,首席科學家Ilya帶頭OpenAI超級對齊團隊取了的實質性成果。他們發表的最新論文,首次確定了超級AI對齊的研究方向:
即小模型監督大模型。
實證表明,GPT-2可以用來激發GPT-4的大部分能力,能夠達到GPT-3.5的性能。甚至還可以泛化到小模型失敗難題上。
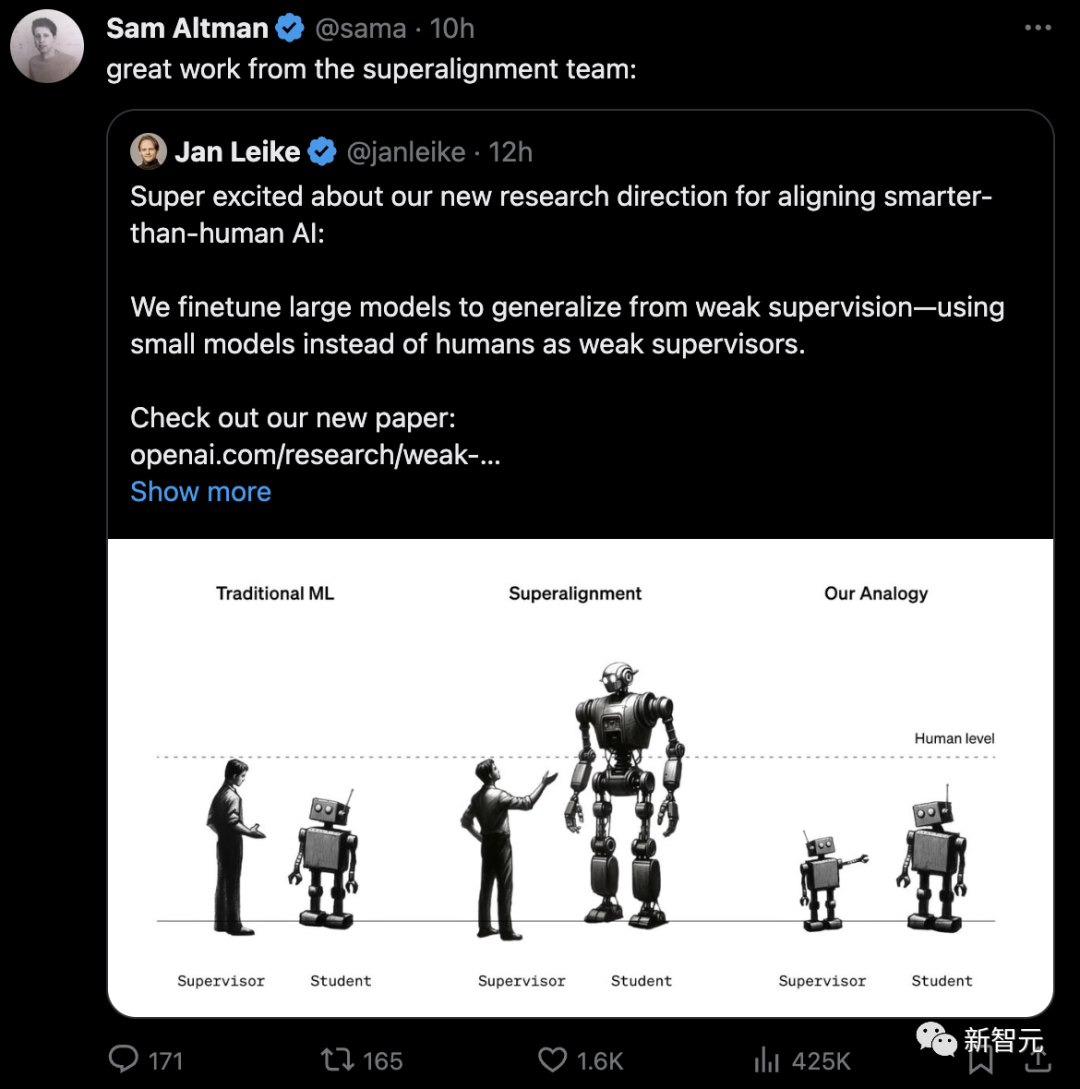
其中,官方博客的第一句便是:我們相信超級智能可能會在未來10年內出現。

再加上傳聞中即將面世的GPT-4.5,以及或許會在明年誕生的GPT-5,OpenAI似乎已經準備好迎接超級人工智能到來了。
然而,在LeCun看來,「超人AI」的發展不會一蹴而就,而是要經歷多個階段逐漸完成。

第一階段:學習世界運作方式
首先,是構建能像小動物一樣學習世界運作方式的系統——可以觀察環境並從中學習,為發展更高級的AI能力打下基礎。而這也是AI進化的關鍵一步。
相比之下,如今的語言模型如GPT-4或Gemini,主要關注的還是文本數據,這顯然遠遠不夠。
LeCun經常嘲諷當前AI的一句話是,「如今大模型的智力連貓狗都不如」。甚至在他看來,通往AGI路上,大模型就是在走歪路。

一直以來,他堅信世界有一種「世界模型」,並着力開發一種新的類似大腦的AI架構,目的是通過更真實地模擬現實世界來解決當前系統的局限性,例如幻覺和邏輯上的缺陷。
這也是想要AI接近人類智力水平,需要像嬰兒一樣學習世界運作的方式。
這個世界模型的架構,由6個獨立的模塊組成:配置器模塊、感知模塊、世界模型模塊、成本模塊、短期記憶模塊,以及參与者模塊。
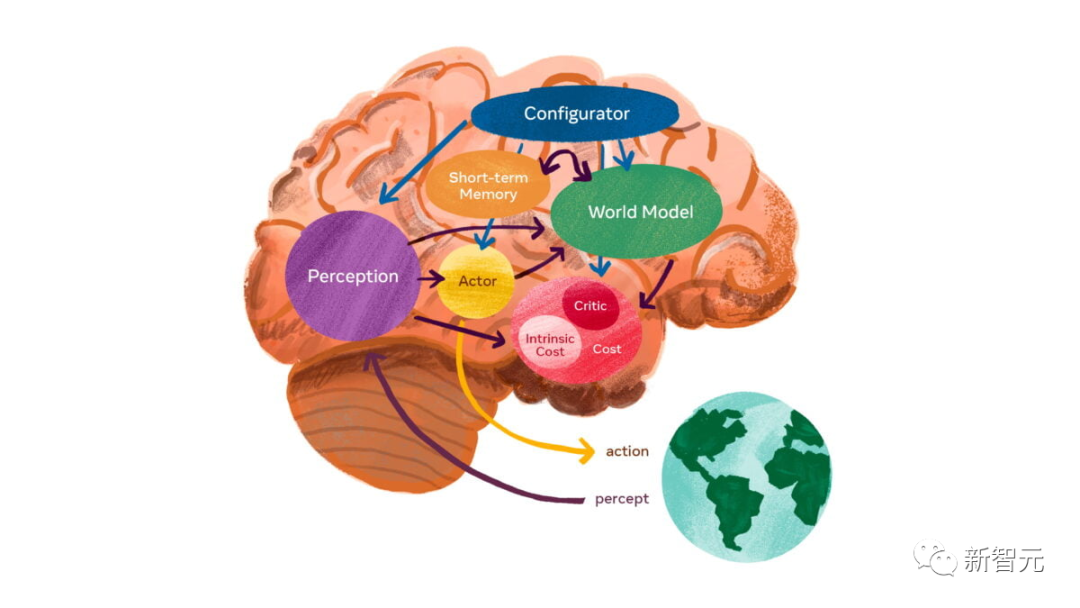
其中,核心是世界模型模塊,旨在根據來自感知模塊的信息預測世界。能夠感知人在向哪移動?汽車是轉彎還是繼續直行?
另外,世界模型必須學習世界的抽象表示,保留重要的細節,並忽略不重要的細節。然後,它必須在與任務水平相適應的抽象級別上提供預測。
LeCun認為「聯合嵌入預測架構」(JEPA)能夠解決這個難題。JEPA支持對大量複雜數據進行無監督學習,同時生成抽象表示。
今年6月,基於「世界模型」的願景,他又提出了一個全新架構I-JEPA。

論文地址:https://ai.meta.com/blog/yann-lecun-ai-model-i-jepa/
不過,LeCun更高層次的願景留下了許多未解決的問題,例如關於世界模型的架構和訓練方法的細節。
第二階段:目標驅動且有保護措施的系統
其次,是構建目標驅動並在一定的保護措施下運作的機器。
這些保護措施將確保AI系統在追求目標時仍然安全可控。
第三階段:規劃與推理
隨着AI系統的不斷成熟,它們將發展出規劃和推理的能力,從而在遵守安全規範的前提下,實現既定目標。
這將使AI系統能夠基於對世界的理解做出更加明智的決策,並採取合適的行動。

第四階段:分層規劃
再進一步,AI系統將能夠進行分層規劃,從而大幅提升決策能力。
這將使AI系統更加高效地處理複雜任務和難題。
第五階段:增強機器智能
隨着AI的進化,這些系統的智能將從最初的老鼠提升至類似狗或者烏鴉的水平。
在此過程中,為確保AI系統保持可控和安全,將需要不斷對其保護措施進行調整。
第六階段:更廣泛的訓練與微調
當AI系統達到一定的智能水平時,就需要將它們放在不同環境和任務中接受訓練,使其更加靈活,能夠應對各種挑戰。
隨後,還需要對AI系統進行微調,以便在特定任務上表現出色。
第七階段:超人類AI的時代
總有一天,我們開發的AI系統會在幾乎所有的領域超越人類智能。
但這並不意味着這些系統具備情感或意識。只不過是在執行任務方面,會比人類做得更好。
同時,即使這些高級AI系統智力超群,它們也必須始終受到人類的控制。
根據LeCun之前提出的觀點,這理論上是可行的:由於智力水平與主導慾望之間並無直接聯繫,而AI並不像人類那樣具有天生的主導慾望。因此,AI或許會願意為智力上不及它們的人類服務。
當然,這種情況在未來5年內不太可能出現。
LLM自我迭代,走向AGI
為了讓超級AI系統能夠迭代學習,持續完成任務並不斷改進效果,當前的許多框架採用了可識別的過程。
類似於下圖中的結構,包括反饋控制和強化學習。
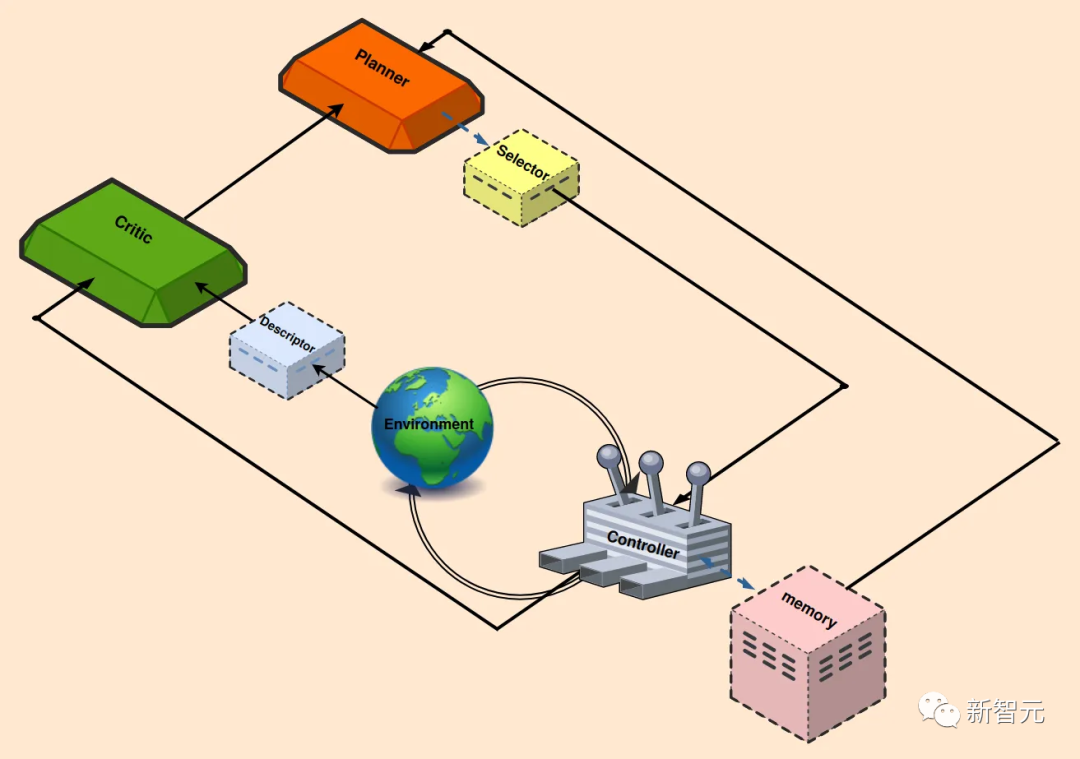
另外,還可以採用一些附加功能,以最大限度地減少人工輸入並增強流程自動化。
那麼,上面展示的迭代學習系統是如何運行的?
首先,人類將廣義定義的任務分配給智能體。
任務通常採取提示的形式,概述主要目標,例如,「探索環境,並完成盡可能多的不同任務」。
Planner(規劃)模塊以這個目標為條件,將目標分解為一系列可執行的、可理解的任務。
由於LLM已經在大量數據上進行了訓練,充分了解智能體運行的環境,可以很好地支持目標分解。此外,還可以補充上下文來增強LLM的性能。
當Planner提供了一組派生的子任務后,Selector負責確定最合適的下一個子任務(滿足先決條件,且能產生最佳結果)。
Controller的工作是生成當前子任務所需要的操作。然後,生成的操作被引入到環境中。
在這個過程中,使用Memory塊檢索最相似的學習任務,將它們集成到其正在進行的工作流中。
為了評估最近操作的影響,Critic會監視環境狀態,提供反饋,包括識別缺點和失敗原因等。
Descriptor塊把環境和智能體的狀態描述為文本,作為Critic的輸入,然後,Critic為Planner提供全面的反饋,以協助進行下一次試驗。

下面來看一下系統中每個模塊的一些具體細節。
規劃(Planner)
Planner負責組織整個任務,根據智能體的當前狀態和水平來協調學習過程。
通常會假設基於LLM的Planner在訓練中接觸過類似的任務分解過程,但這個假設在這裏並不成立。
因此,研究人員提出了一種方法:從環境手冊文本中提取所有相關信息,總結成一個小尺寸的上下文,並連接到提示中。
在現實生活中的應用程序中,智能體會遇到各種不同複雜程度的環境,這種簡單而有效的方法,可以避免頻繁為新任務進行微調。
Planner模塊與VOYAGER和DEPS在某些方面類似。
VOYAGER使用 GPT-4作為自動課程模塊,試圖根據探索進度和智能體的狀態提出越來越難的任務。它的提示包括:
在設定約束條件的同時鼓勵探索;
當前智能體的狀態;
以前完成和失敗的任務,
來自另一個GPT-3.5自問答模塊的任何其他上下文。
然後,VOYAGER輸出要由智能體完成的任務。
DEPS在不同環境中使用CODEX、GPT-4、ChatGPT和GPT-3作為LLM規劃器,提示內容包括:
強大的最終目標(例如,在Minecraft環境中獲得鑽石);
最近生成的計劃;
對環境的描述和解釋。
為了提高計劃的效率,DEPS還提出了一個狀態感知選擇器,從規劃器生成的候選目標集中,根據當前狀態選擇最近的目標。
在複雜的環境中,通常存在多個可行的計劃,優先考慮更接近的目標可以提高計劃效率。
為此,研究人員使用離線軌跡訓練了一個神經網絡,根據在當前狀態下完成給定目標所需的時間步長進行預測和排名。然後,Planner與Selector協作生成一系列要完成的任務。
控制(Controller)
Controller的職責是選擇下一個動作來完成給定的任務。
Controller可以是一個LLM(例如VOYAGER),也可以是深度強化學習模型(例如DEPS),根據狀態和給定任務生成操作。
VOYAGER在交互式提示中使用GPT-4來扮演控制器的角色。
VOYAGER、Progprompt和CaP選擇使用代碼作為操作空間,因為代碼可以自然地表示時間擴展和組合操作。在VOYAGER中生成代碼的提示包括:
代碼生成動機指南;
可用的控制基元API列表及其描述;
從記憶中檢索到的相關技能或代碼;
上一輪生成的代碼、環境反饋、執行錯誤、Critic輸出;
當前狀態;
思維鏈提示在代碼生成前進行推理。
記憶(Memory)
人類的記憶一般可以分為短期記憶和長期記憶:
短期記憶存儲用於學習和推理等任務的信息,可容納大約7件物品,持續約20-30秒。
所有基於LLM的終身學習方法,都是通過上下文學習來使用短期記憶,而上下文學習受到LLM上下文長度的限制。
長期記憶用於長時間存儲和檢索信息,可以作為具有快速檢索功能的外部向量存儲來實現。
VOYAGER通過添加/檢索從外部向量存儲中學習到的技能,從長期記憶中受益。
如下圖所示,上半部分描述了VOYAGER添加新技能的過程,下半部分表示技能檢索。
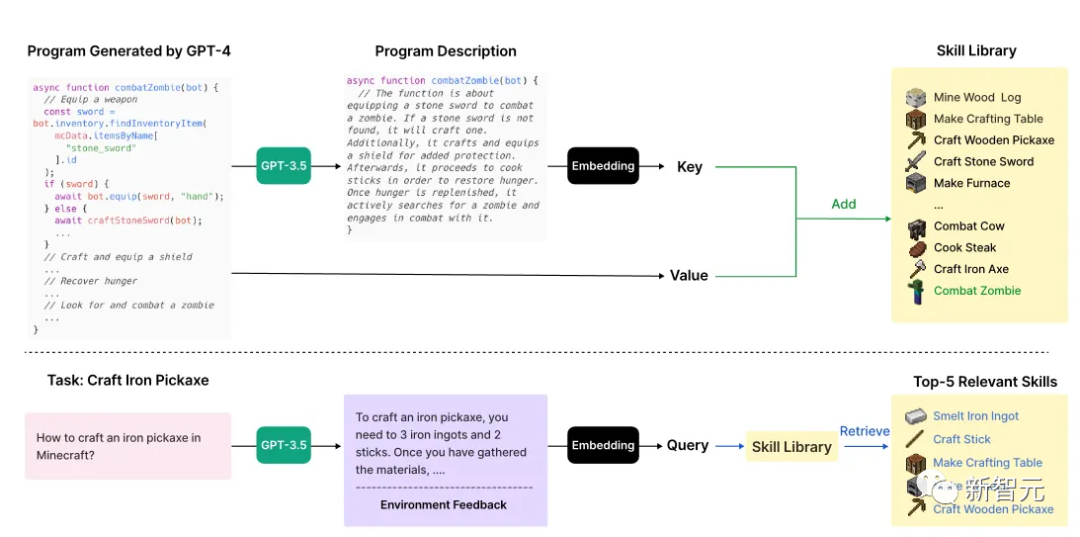
當Critic驗證代碼可以完成任務時,使用GPT-3.5生成代碼的描述。
然後,技能將被以鍵值對的形式(技能描述和代碼)存儲在技能庫中。
當Planner生成一項新任務時,GPT-3.5會生成新的描述,然後從技能庫中檢索前5個相關技能。
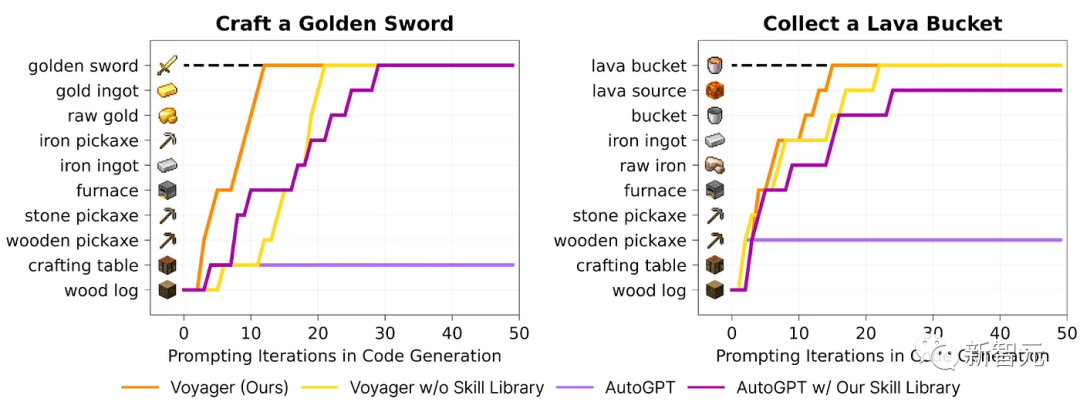
添加長期內存可以顯著提高性能。上圖展示了技能庫對VOYAGER的重要性。
Controller同時利用短期記憶和長期記憶,以生成和完善其策略。
評論(Critic)
Critic也是一個基於LLM的模塊,它對先前執行的計劃進行點評,並提供反饋。
Critic可以採用GPT-4,利用獎勵信號、當前軌跡以及持久記憶來生成反饋,這種反饋比標量獎勵提供了更多的信息,並存儲在內存中,供Planner用於優化計劃。
描述(Descriptor)
在基於LLM的終身學習中,Planner的輸入和輸出是文本。
雖然很多環境(如Crafter)是基於文本的,但有一些其他環境,會返回2D或3D圖像的渲染,或者返回一些狀態變量。
這時,Descriptor就可以充當中間的橋樑,將其他模態轉換為文本,並將它們合併到LLM的提示中。
自主AI智能體
以上主要討論了將基礎模型與持續學習相結合的最新研究,這是實現AGI的重要一步。
而最近的AutoGPT和BabyAGI等幾個工作又帶給人們新的啟發。
這些系統接受任務后,將任務分解為子任務,自動進行提示和響應,並重複執行,直到實現提供的目標。
他們還可以訪問不同的API,或者訪問互聯網,大大擴展自己的應用範圍。
AutoGPT可以訪問互聯網,並能夠與在線和本地的應用程序、軟件和服務進行交互。
為了實現人類給出的更高層次的目標,AutoGPT使用一種稱為Reason and ACT (ReACT)的提示格式。
ReACT使智能體能夠接收輸入、理解並採取行動、根據結果進行推理,然後在需要時重新運行該循環。
由於AutoGPT可以自己提示自己,所以可以在完成任務的同時進行思考和推理,尋找解決方案,丟棄不成功的解決方案,並考慮不同的選擇。
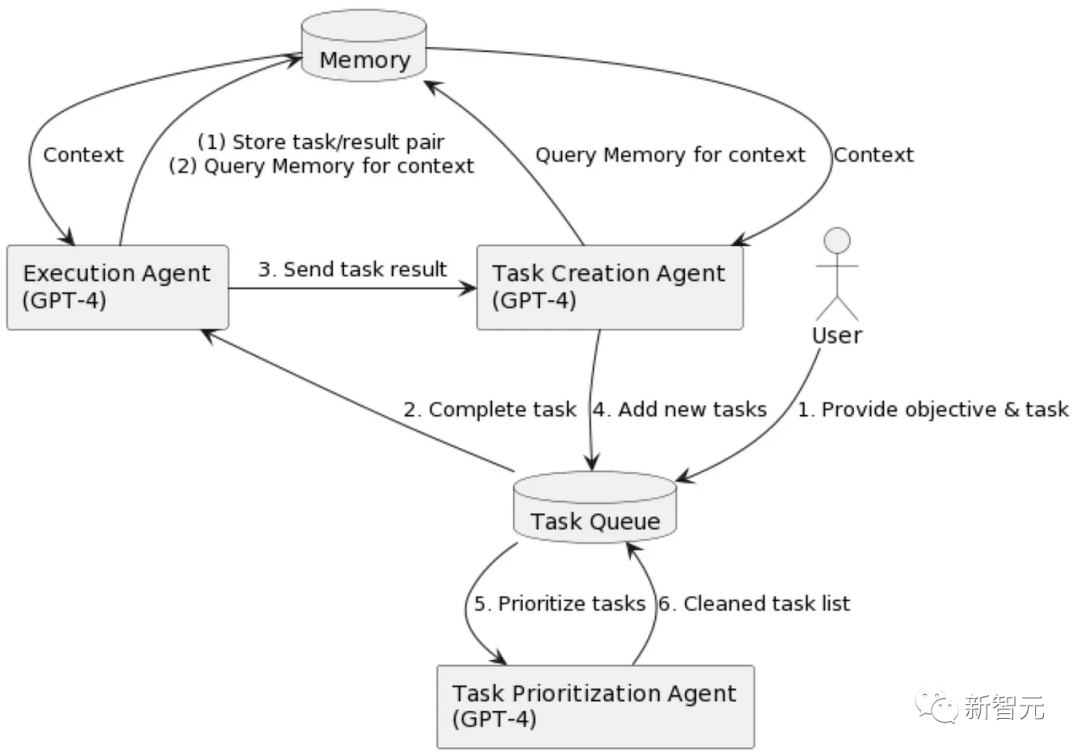
BabyAGI是另一個最近推出的自主AI智能體,上面是它的流程圖。它有三個基於LLM的組件:
任務創建智能體:提出了一個任務列表(類似於Planer);
優先級智能體:嘗試通過LLM提示(類似於Selector)確定任務列表的優先級;
執行智能體(類似於Controller):執行具有最高優先級的任務。
AutoGPT和BabyAGI都使用向量數據庫來存儲中間結果並從經驗中學習。
局限性和挑戰
不過,大語言模型(LLM)在終身學習過程中仍然存在一些問題。
首先就是模型有時會出現幻覺、捏造事實或安排不存在的任務,而且在一些研究中,將GPT-4換成GPT-3.5會嚴重影響性能。
其次,當大語言模型扮演規劃者(Planner)或評論者(Critic)時,它們的表現可能不夠準確。——比如評論者可能提供錯誤的反饋,而規劃者可能重複同樣的計劃。
另外,大語言模型的上下文長度限制了它們的短期記憶能力,這影響了模型保存詳細的過往經驗、具體指令和控制原語API。
最後,多數研究假設大語言模型已經掌握了進行終身學習所需的全部信息,但這種假設並不總是成立。
所以研究人員為智能體提供互聯網訪問(如AutoGPT),或提供文本材料作為輸入上下文(如本文介紹),這些方法對之後的研究提供了幫助。
參考資料:
- https://the-decoder.com/heres-how-we-get-to-superhuman-ai-according-to-metas-yann-lecun/
- https://towardsdatascience.com/towards-agi-llms-and-foundational-models-roles-in-the-lifelong-learning-revolution-f8e56c17fa66