所有語言











分享
8x7B開源MoE擊敗Llama 2逼近GPT-4!歐版OpenAI震驚AI界,22人公司半年估值20億
巴比特_AIcore699天前
前幾日,一條MoE的磁力鏈接引爆AI圈。剛剛出爐的基準測試中,8*7B的小模型直接碾壓了Llama 2 70B!網友直呼這是初創公司版的超級英雄故事,要趕超GPT-4隻是時間問題了。有趣的是,創始人姓氏的首字母恰好組成了「L.L.M.」。
原文來源:新智元

圖片來源:由無界 AI生成
開源奇迹再一次上演:Mistral AI發布了首個開源MoE大模型。
幾天前,一條磁力鏈接,瞬間震驚了AI社區。
87GB的種子,8x7B的MoE架構,看起來就像一款mini版「開源GPT-4」!
無發布會,無宣傳視頻,一條磁力鏈接,就讓開發者們夜不能寐。
這家成立於法國的AI初創公司,在開通官方賬號后僅發布了三條內容。
6月,Mistral AI上線。7頁PPT,獲得歐洲歷史上最大的種子輪融資。
9月,Mistral 7B發布,號稱是當時最強的70億參數開源模型。
12月,類GPT-4架構的開源版本Mistral 8x7B發布。幾天後,外媒金融時報公布Mistral AI最新一輪融資4.15億美元,估值高達20億美元,翻了8倍。
如今20多人的公司,創下了開源公司史上最快增長紀錄。

所以,閉源大模型真的走到頭了?
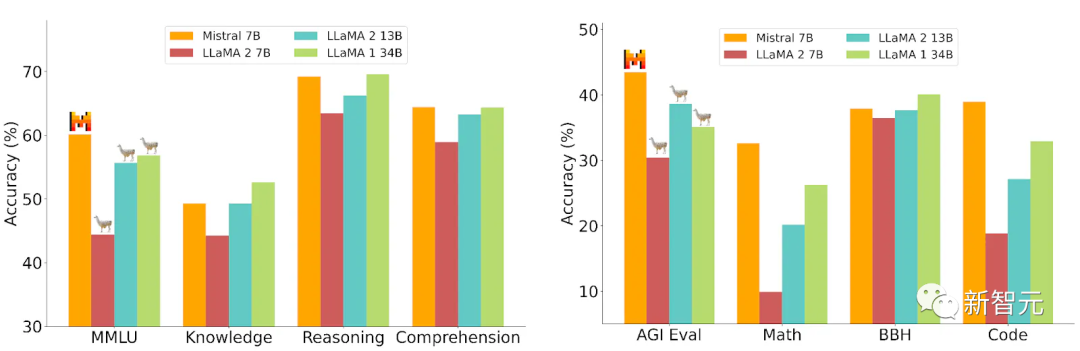
8個7B小模型,趕超700億參數Llama 2
更令人震驚的是,就在剛剛,Mistral-MoE的基準測試結果出爐——
可以看到,這8個70億參數的小模型組合起來,直接在多個跑分上超過了多達700億參數的Llama 2。
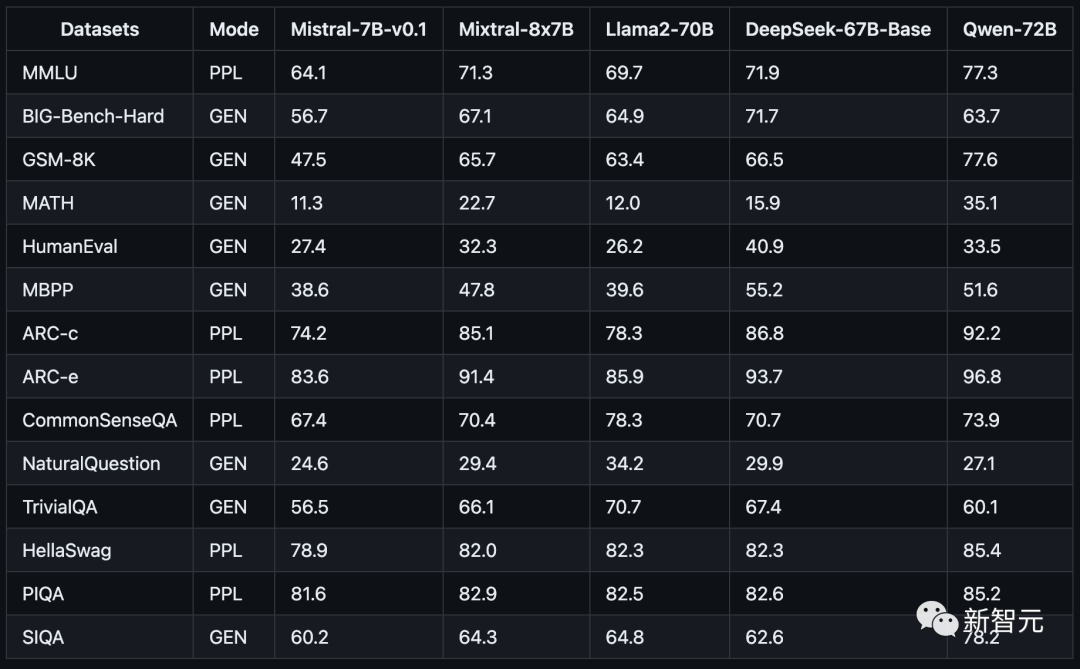
來源:OpenCompass
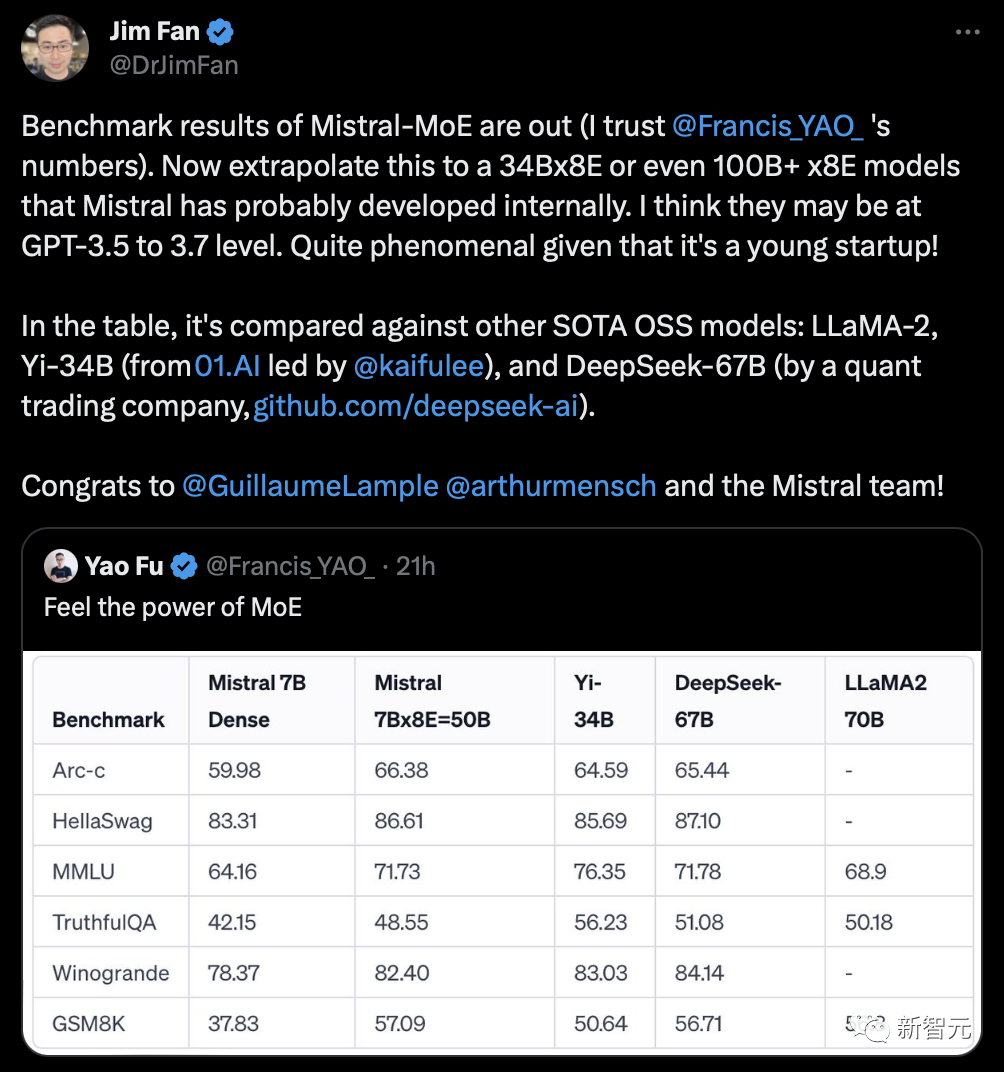
英偉達高級研究科學家Jim Fan推測,Mistral可能已經在開發34Bx8E,甚至100B+x8E的模型了。而它們的性能,或許已經達到了GPT-3.5/3.7的水平。
這裏簡單介紹一下,所謂專家混合模型(MoE),就是把複雜的任務分割成一系列更小、更容易處理的子任務,每個子任務由一個特定領域的「專家」負責。
1. 專家層:這些是專門訓練的小型神經網絡,每個網絡都在其擅長的領域有着卓越的表現。
2. 門控網絡:這是MoE架構中的決策核心。它負責判斷哪個專家最適合處理某個特定的輸入數據。門控網絡會計算輸入數據與每個專家的兼容性得分,然後依據這些得分決定每個專家在處理任務中的作用。
這些組件共同作用,確保適合的任務由合適的專家來處理。門控網絡有效地將輸入數據引導至最合適的專家,而專家們則專註於自己擅長的領域。這種合作性訓練使得整體模型變得更加多功能和強大。

有人在評論區發出靈魂拷問:MoE是什麼?
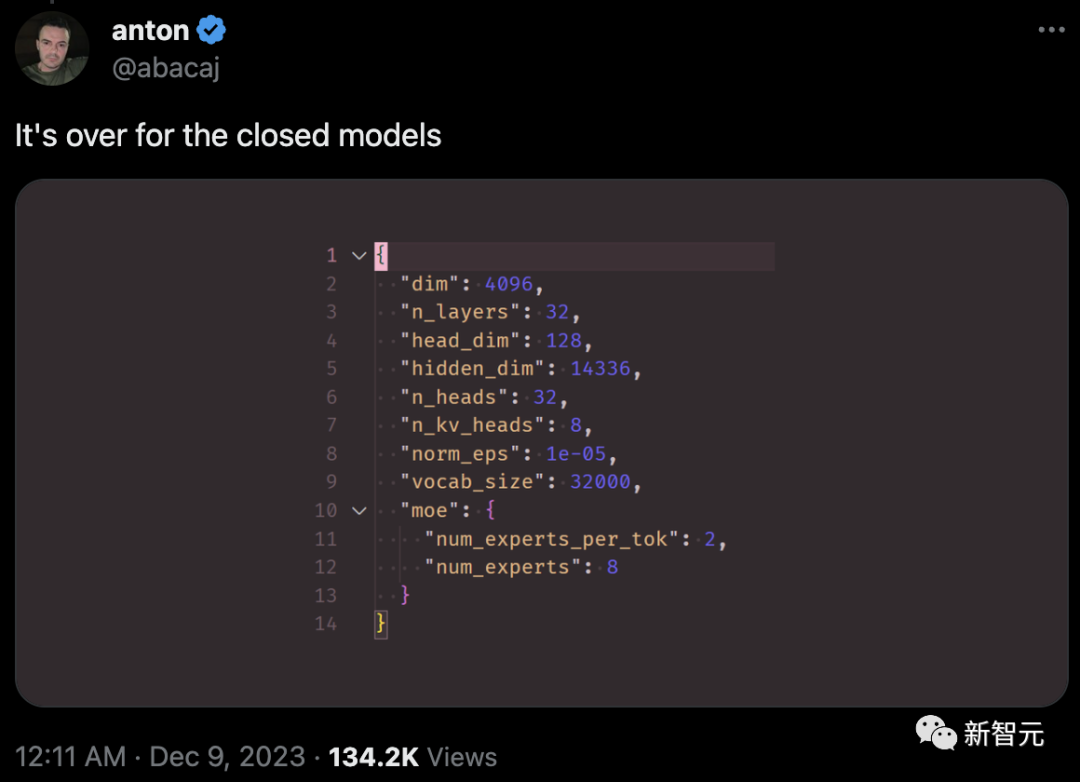
根據網友分析,Mistral 8x7B在每個token的推理過程中,只使用了2個專家。
以下是從模型元數據中提取的信息:
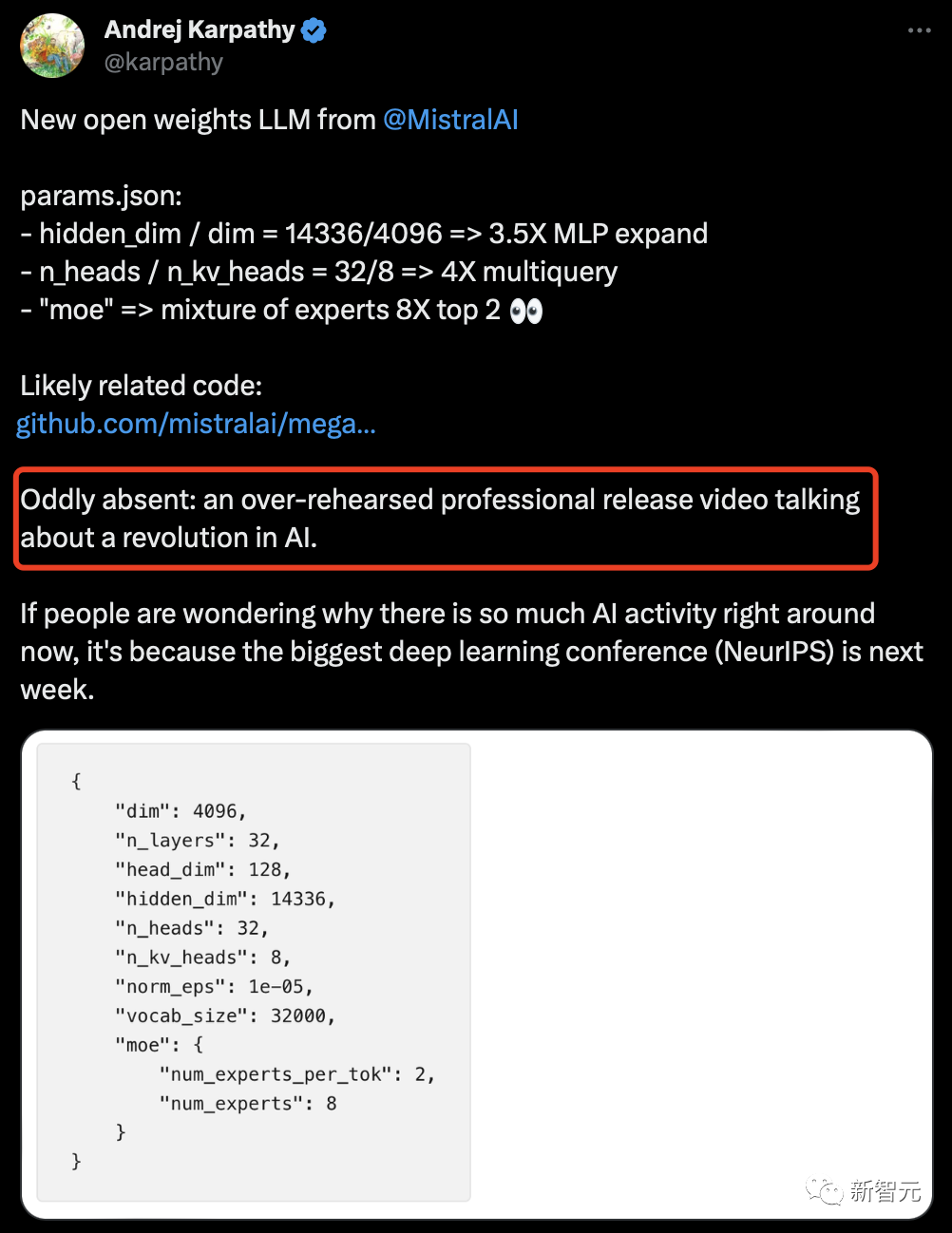
{"dim": 4096, "n_layers": 32, "head_dim": 128, "hidden_dim": 14336, "n_heads": 32, "n_kv_heads": 8, "norm_eps": 1e-05, "vocab_size": 32000, "moe": {"num_experts_per_tok": 2, "num_experts": 8}
與GPT-4(網傳版)相比,Mistral 8x7B具有類似的架構,但在規模上有所縮減:
- 專家數量為8個,而不是16個(減少了一半)
- 每個專家擁有70億參數,而不是1660億(減少了約24倍)
- 總計420億參數(估計值),而不是1.8萬億(減少了約42倍)
- 與原始GPT-4相同的32K上下文窗口

此前曾曝出,GPT-4很可能是由8個或者是16個MoE構成
目前,已經有不少開源模型平台上線了Mistral 8×7B,感興趣的讀者可以親自試一試它的性能。
LangSmith:https://smith.langchain.com/
Perplexity Labs:https://labs.perplexity.ai/
OpenRouter:https://openrouter.ai/models/fireworks/mixtral-8x7b-fw-chat
超越GPT-4,只是時間問題?
網友驚呼,Mistral AI才是OpenAI該有的樣子!

有人表示,這個基準測試結果,簡直就是初創公司版本的超級英雄故事!
無論是Mistral和Midjourney,顯然已經破解了密碼,接下來,要超越GPT-4隻是問題。

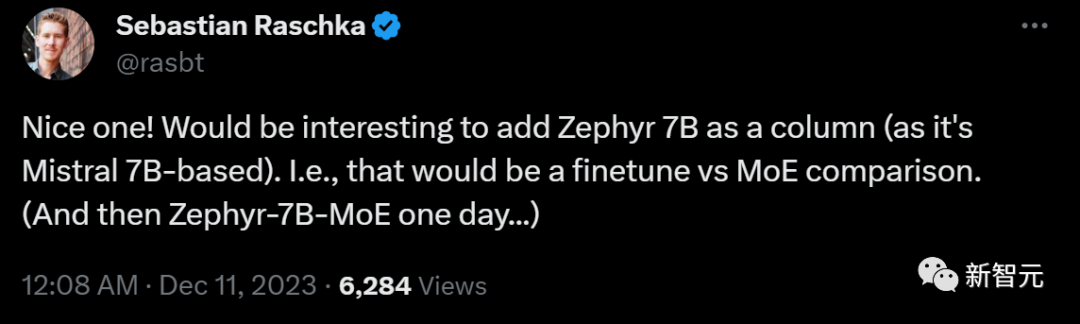
深度學習大牛Sebastian Raschka表示,基準測試中最好再加入Zephyr 7B這一列,因為它是基於Mistral 7B的。這樣,我們就可以直觀地看出Mistral微調和Mistral MoE的對比。
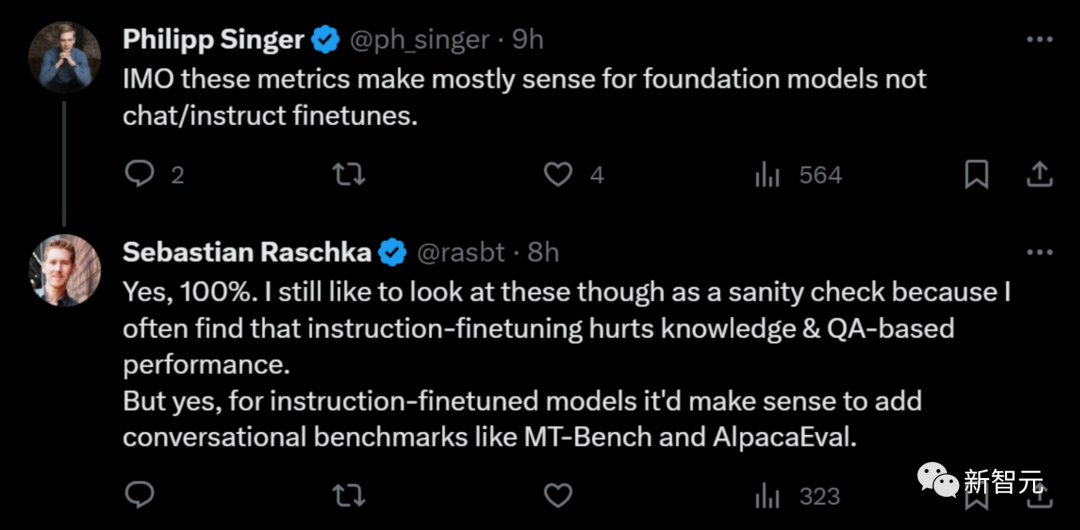
有人表示質疑:這些指標主要是對基礎模型有意義,而不是對聊天/指令微調。
Raschka回答說,沒錯,但這仍然可以看作是一種健全性檢測,因為指令微調經常會損害模型的知識,以及基於QA的性能。
對於指令微調模型,添加MT-Bench和AlpacaEval等對話基準測試是有意義的。
並且,Raschka也強調,自己只是假設Mistral MoE沒有經過指令微調,現在急需一份paper。
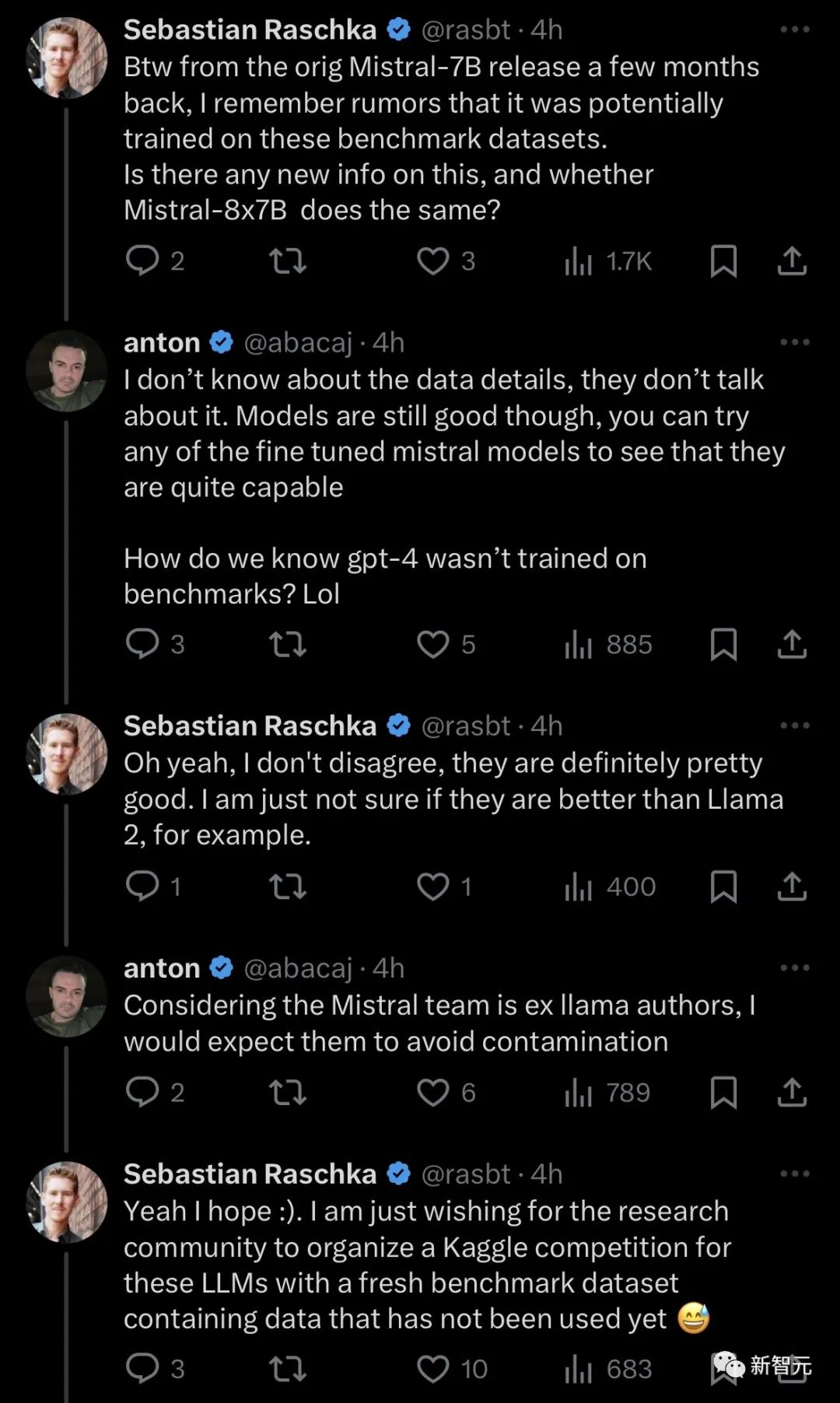
而且,Raschka也懷疑道:Mistral MoE真的能超越Llama 2 7B嗎?
幾個月前就有傳言,說原始的Mistra 7B模型可能在基準數據集上進行了訓練,那麼這次的Mistral 8x7B是否也是如此?
軟件工程師Anton回答說,我們也並不能確定GPT-4沒有在基準測試上訓練。考慮到Mistral團隊是前Llama的作者,希望他們能避免污染的問題。
Raschka表示,非常希望研究界為這些LLM組織一場Kaggle競賽,其中一定要有包含尚未使用數據的全新基準數據集。
也有人討論到,所以現在大模型的瓶頸究竟是什麼?是數據,計算,還是一些神奇的Transformer微調?
這些模型之間最大的區別,似乎只是數據集。OpenAI有人提到過,他們訓練了大量的類GPT模型,與訓練數據相比,架構更改對性能的影響不大。

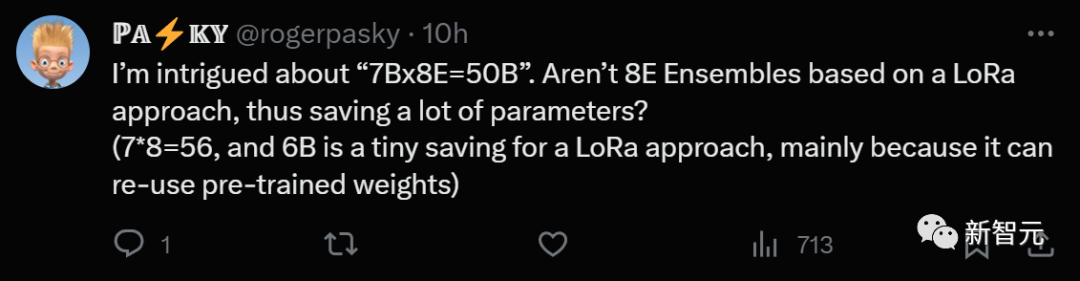
有人表示,對「7Bx8E=50B」的說法很感興趣。是否是因為此處的「集成」是基於LoRa方法,從而節省了很多參數?
(7x8=56,而6B對於LoRa方法來說節省得很少,主要是因為它可以重複使用預訓練權重)
有人已經期待,有望替代Transformer的全新Mamba架構能夠完成這項工作,這樣Mistral-MoE就可以更快、更便宜地擴展。
OpenAI科學家Karpathy的言語中,還暗戳戳嘲諷了一把谷歌Gemini的虛假視頻演示。

畢竟,比起提前剪輯好的視頻demo,Mistral AI的宣傳方式實在太樸素了。
不過,對於Mitral MoE是第一個開源MoE大模型的說法,有人出來辟了謠。
在Mistral放出這個開源的7B×8E的MoE之前,英偉達和谷歌也放出過其他完全開源的MoE。
曾在英偉達實習的新加坡國立大學博士生Fuzhao Xue表示,他們的團隊在4個月前也開源了一個80億參數的MoE模型。
成立僅半年,估值20億
由前Meta和谷歌研究人員創立,這家總部位於巴黎的初創公司Mistral AI,僅憑6個月的時間逆襲成功。
值得一提的是,Mistral AI已在最新一輪融資中籌集3.85億歐元(約合4.15億美元)。

這次融資讓僅有22名員工的明星公司,估值飆升至約20億美元。
這次參与投資的,包括硅谷的風險投資公司Andreessen Horowitz(a16z)、英偉達、Salesforce等。

6個月前,該公司剛剛成立僅幾周,員工僅6人,還未做出任何產品,卻拿着7頁的PPT斬獲了1.13億美元巨額融資。
現在,Mistral AI估值相當於翻了近10倍。
說來這家公司的名頭,可能並不像OpenAI名滿天下,但是它的技術能夠與ChatGPT相匹敵,算得上是OpenAI勁敵之一。
而它們分別是兩個極端派————開源和閉源的代表。

Mistral AI堅信其技術以開源軟件的形式共享,讓任何人都可以自由地複製、修改和再利用這些計算機代碼。
這為那些希望迅速構建自己的聊天機器人的外部開發者提供了所需的一切。
然而,在OpenAI、谷歌等競爭對手看來,開源會帶來風險,原始技術可能被用於傳播假信息和其他有害內容。
Mistral AI背後開源理念的起源,離不開核心創始人,創辦這家公司的初心。
今年5月,Meta巴黎AI實驗室的研究人員Timothée Lacroix和Guillaume Lample,以及DeepMind的前員工Arthur Mensch共同創立Mistral AI。

論文地址:https://arxiv.org/pdf/2302.13971.pdf
人人皆知,Meta一直是推崇開源公司中的佼佼者。回顧2023年,這家科技巨頭已經開源了諸多大模型,包括LLaMA 2、Code LLaMA等等。
因此,不難理解Timothée Lacroix和Guillaume Lample創始人從前東家繼承了這一傳統。

有趣的是,創始人姓氏的首字母恰好組成了「L.L.M.」。
這不僅是姓名首字母簡寫,也恰好是團隊正在開發的大語言模型(Large Language Model)的縮寫。
這場人工智能競賽中,OpenAI、微軟、谷歌等科技公司早已成為行業的佼佼者,並在LLM研发上上斥資數千億美元。
憑藉充足的互聯網數據養料,使得大模型能自主生成文本,從而回答問題、創作詩歌甚至寫代碼,讓全球所有公司看到了這項技術的巨大潛力。
因此OpenAI、谷歌在發布新AI系統前,都將花費數月時間,做好LLM的安全措施,防止這項技術散播虛假信息、仇恨言論及其他有害內容。
Mistral AI的首席執行官Mensch表示,團隊為LLM設計了一種更高效、更具成本效益的訓練方法。而且模型的運行成本不到他們的一半。
有人粗略估計,每月大約300萬美元的Mistral 7B可以滿足全球免費ChatGPT用戶100%的使用量。

他們對自家模型的既定目標,就是大幅擊敗ChatGPT-3.5,以及Bard。

然而,很多AI研究者、科技公司高、還有風險投資家認為,真正贏得AI競賽的將是——那些構建同樣技術並免費提供給大眾的公司,且不設任何安全限制。
Mistral AI的誕生,如今被視為法國挑戰美國科技巨頭的一個機遇。
自互聯網時代開啟以來,歐洲鮮有在全球影響重大的科技公司,但在AI領域,Mistral AI讓歐洲看到了取得進展的可能。
另一邊,投資者們正大力投資那些信奉「開源理念」的初創公司。

去年12月,曾在OpenAI和DeepMind擔任研究科學家創立了Perplexity AI,在最近完成了一輪7000萬美元的融資,公司估值達到了5億美元。
風險投資公司a16z的合伙人Anjney Midha對新一輪Mistral的投資表示:
我們堅信 AI 應該是開放源代碼的。推動現代計算的許多主要技術都是開源的,包括計算機操作系統、編程語言和數據庫。廣泛分享人工智能底層代碼是最安全的途徑,因為這樣可以有更多人參與審查這項技術,發現並解決潛在的缺陷。
沒有任何一個工程團隊能夠發現所有問題。大型社區在構建更便宜、更快、更優、更安全的軟件方面更有優勢。
創始人Mensch在採訪中透露,公司目前還沒有盈利,不過會在「年底前」發生改變。
目前,Mistral AI已經研發了一個訪問AI模型的新平台,以供第三方公司使用。
參考資料:
https://www.nytimes.com/2023/12/10/technology/mistral-ai-funding.html
https://twitter.com/DrJimFan/status/1733864317227786622
https://github.com/open-compass/MixtralKit/blob/main/README_zh-CN.md