所有語言











分享
為什麼說AI現在還不行?
巴比特_AIcore651天前
原文來源:琢磨事
文 | 李智勇

圖片來源:由無界 AI生成
AI最近有點被妖魔化了,很像一個老虎在還沒有橘貓大的時候,就已經被天天當成虎力大仙來討論。這種普遍的高預期其實是有害的,尤其是當事情本身還需要耐心細緻深耕且長跑的時候。資本、品牌可以匹配高預期所對應的增長倍數,業務則不行,業務先天擠出一切泡沫。也正因此最近寫了幾篇文章都在提應該以一種更加理性的態度來看待AI的進展,甚至設想了一種測試智能程度的方式:圖靈測試2.0。這篇文章則是對此前各文章的綜合。
AIGC的GC(內容生成)是支點也是鎖鏈
顯然的AI是一種基礎設施,它在重定義計算的內涵和方式。
如果和過去對比,那麼過去的編程固化的是程序員的智能,程序員的智能通過程序在限定的邊界內處理問題,所以泛IT的崛起伴隨着程序員群體的崛起,不管是程序員的人數還是收入。AI則在很大程度上摺疊這个中間環節,對話即計算,同時讓這種計算變的更加泛化和無邊界。從這個角度看,AI的崛起註定伴隨着程序員群體的衰落(首先是人數上,但不是說這行當就沒了)。
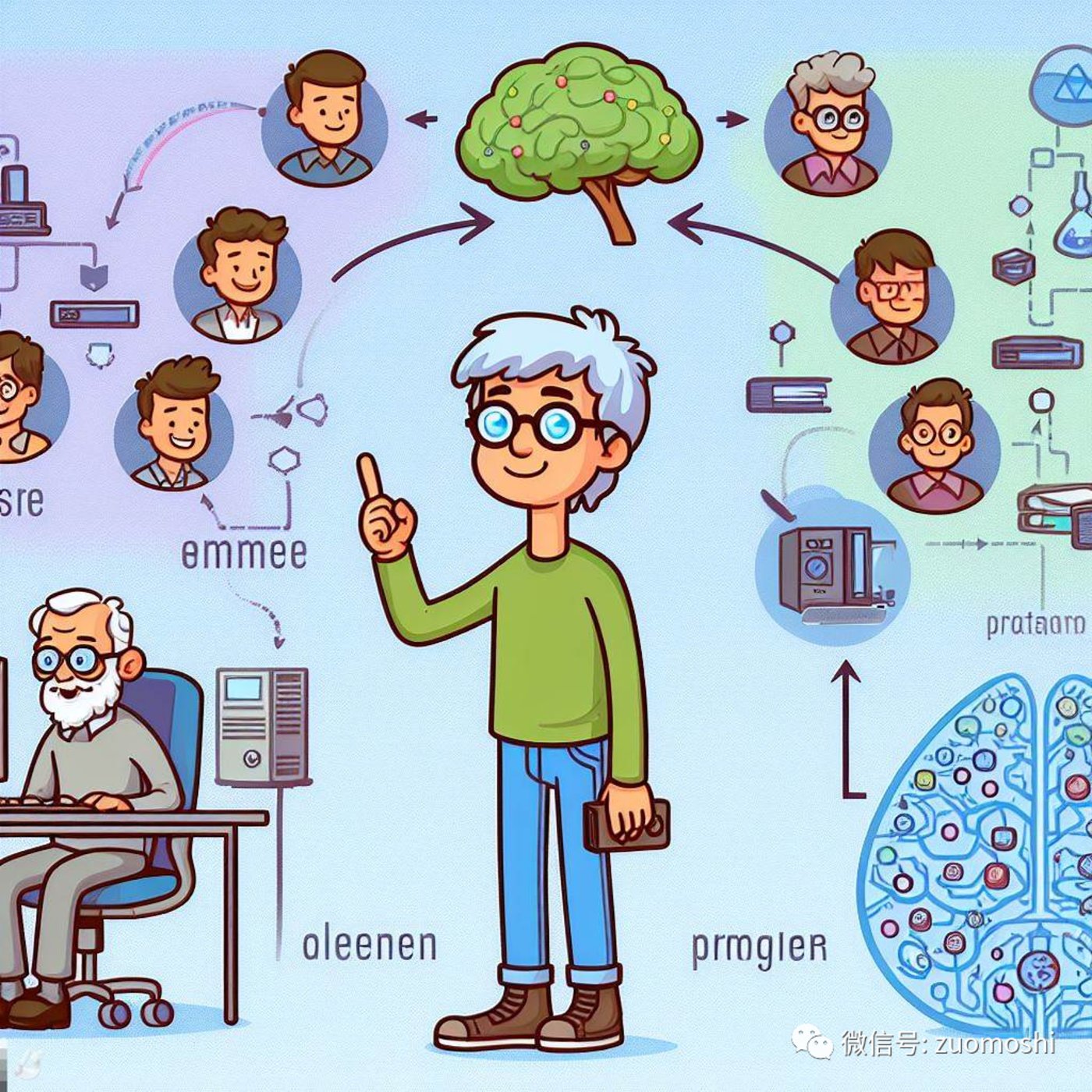
(用戶--程序員--程序--電腦--互聯網的計算模式)

(用戶--人工智能的計算模式)
基礎設施的最終成敗好壞一定在於外部,而不在於它自己的特徵比如是否優秀、大模型到底多大等。在過去微內核操作系統一度眾望所歸,但其實不管Linux還是Windows都不是微內核,純粹的微內核系統比如Minix卻只是教具。
作為基礎設施的AI也一樣,要想成功那就必須走出單純內容生成工具的範疇,變成一種通用計算平台,為各種場合提供新計算方式。
過去不管Windows還是Linux都提供了這種通用性,從取款機到機場的大屏,再到家裡的機頂盒,甚至有點智能的鬧鐘都是他們在提供基礎的計算能力。(有時候這些系統會崩潰,讓人驚訝的是不是崩潰而是看到好多系統其實是XP的)。
AI打破內容生成工具的界限后,就會變成這個新的計算底座(通用人工智能的通用對應的就是這個情境)。也只有成為這種通用的計算底座后,AI才真正迎來自己的星辰大海。
在現在的內容生成式AI和這種通用計算底座之間現在橫亘着一道無形的基因鎖鏈一樣的界限。
這個基因鎖鏈就是內容生成工具的邊界。
AIGC的GC(內容生成)是支點也是鎖鏈。
在工具範疇里,這次AI其實已經做的足夠好,就是池子太小,如果就做這個會憋死所有人。
GC工具池子太小做的人太多,會憋死所有人
我們拿個具體例子來看下為什麼說這個池子太小。
起點中文網上有個網文作家筆名叫做我吃西紅柿,這個1987年的同學本來是蘇州大學數學專業的一名大學生,按正常軌跡畢業后大概率不能繼續做數學相關的工作,那時候就業很可能會做程序員等相關方向。但他沒走尋常路,在大學期間開始了網文創作,取得了很好的成績,2012年11月以2100萬的版稅收入高居“中國網絡作家富豪榜”第2位。
假設他一年寫一部小說3百萬字,放大點算1000萬token。現在這部分自己不寫了,都用AI。隨便選個國內某大模型的報價做參照,按1500元/5000萬token,那這部分給人工智能公司可以創造的收入是300塊,在2100萬收入裏面佔十萬分之一多一點。再放大下,如果有10000個我吃西紅柿,那AIGC在網文行業一共可以賺300萬。這還不夠一個團隊一年的工資,特別高端人才的情況,這甚至不夠一個人的。
如果大模型只做內容生成,創造的價值和行業現有價值大致就是這麼個比例。
而已經很多人衝進來了,這就很像做一個很小的池子里養了一堆鯊魚,餓極了就只能拚命內卷互相殘殺,然後大概率是都死掉了,一條不剩。
如果AI不能在GC之上再進一步,就必然是這個結局:帶着快樂期望的高度內卷。
這種內卷對AI整體來講是徹底的負反饋和死路一條
每個人期望的都是新式通用計算平台和應用,實際上卻只是內容生成工具,創造一點點新價值。長時間怎麼可能不負反饋呢!
那AI怎麼才能走出來呢?答案是需要通過圖靈測試2.0。
圖靈測試2.0
原始的圖靈測試這樣:
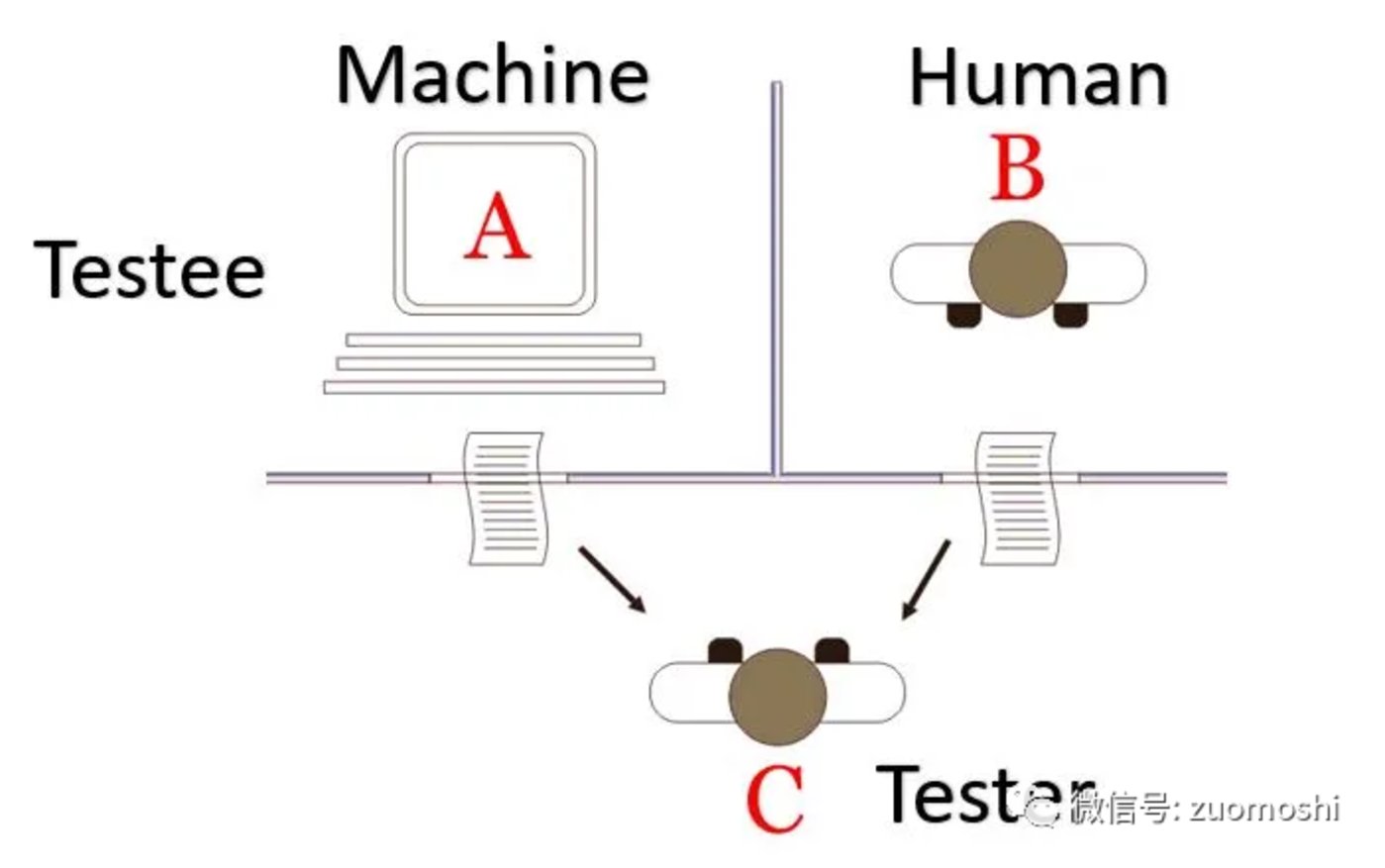
這是一個純粹的智能測試,本質是追求在封閉系統裏面的邏輯自洽性。
現在我們把Agent類似的概念加入這個測試:
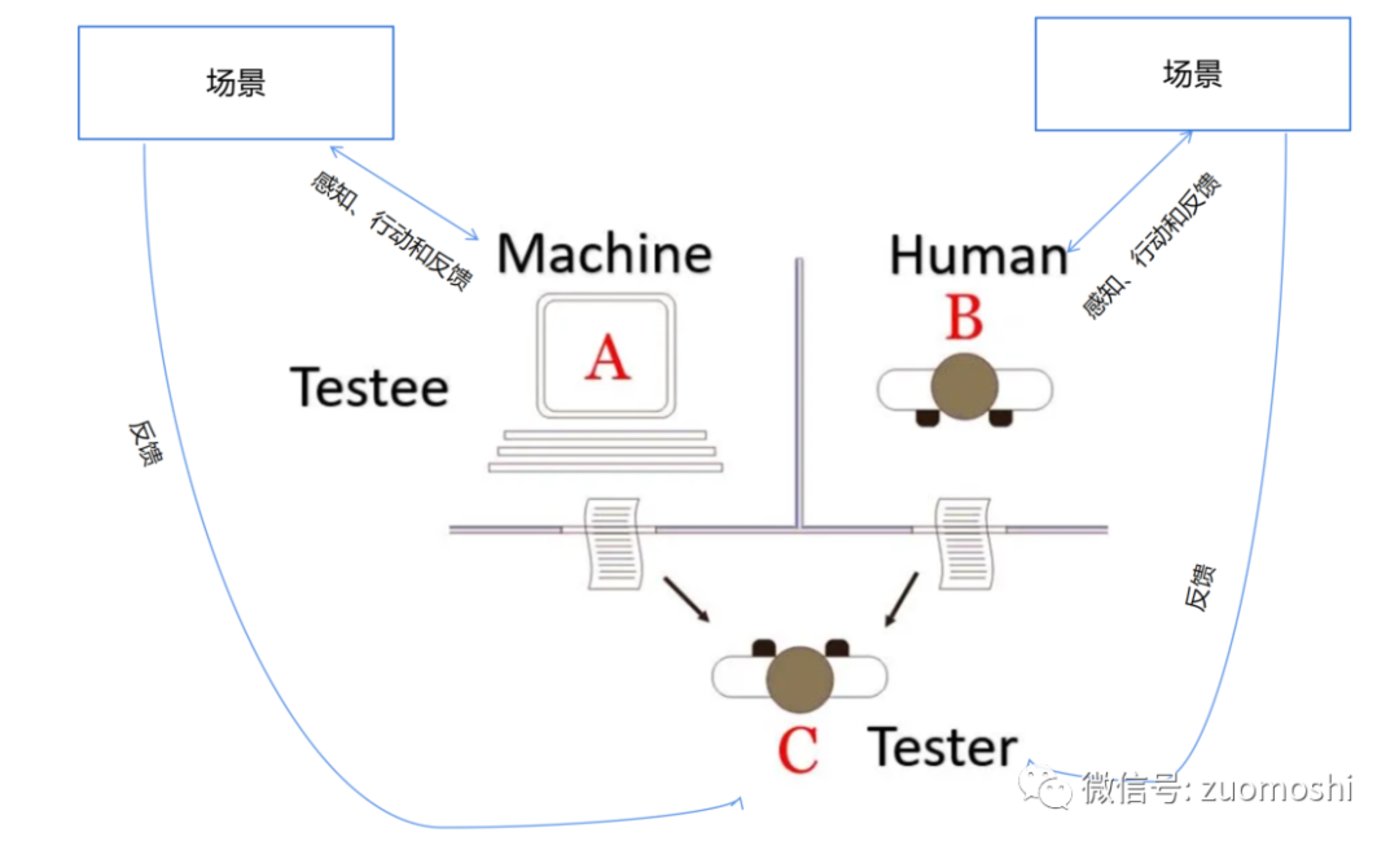
這就是圖靈測試2.0。和1.0相比核心差異是什麼呢?
去幻覺,有邊界。
1.0是一個凌空的系統,具有合理性的幻覺其實有助於通過測試,但2.0不行,測試者同時從真實場景和被測試者接受反饋;其次就是測試邊界的限定要求更高的智能深度。這很像趙括學兵法能說的天花亂墜,但不一定能打仗;會打仗不一定兵法上什麼都懂,但水站、陸戰、馬站好歹得會一個。
能否打破內容生成的邊界變成各種場合都用的新式通用計算平台,關鍵取決於智能是否能跟上。而智能是否能跟上取決於是否在一個個場景下能通過圖靈測試2.0。
Linux和Windows等輸出智能的方式雖然老土,並且但他們提供了足夠的確定性,他們加上程序員達成了過去所謂的軟件吞噬世界。這是一種Good Enough的計算模式,但現在的AI還不是。
現在大模型等確實提供了更好的計算形式,但關鍵是它的不智能(過不了圖靈測試2.0)導致不能替換過去系統加程序員的組合。智能的邊界限制了應用的邊界。
通過圖靈測試2.0後會怎麼樣呢?
那時候不單客服、外呼會基於AI進行構建,每個現有應用(Office等已經開始、遊戲大概率會爆真正的多維敘事高度隨機,主打智能的新式遊戲)、廣告屏、智能音箱、電視甚至手機都會重整。因為基本計算範式變了,它的交互載體必然發生變化,這個變化的幅度可能大於PC互聯網到移動互聯網的更迭幅度。從這個角度可以進機器人一定是下個通用計算平台型產品。
極端講除了極其机械的那類產品比如霓虹燈,計算器,別的都會變。
這種視角可以描述成為場景的智能密度,顯然的擰螺絲的智能密度度低於算數學題。
智能密度越高的場景其計算方式和對應的產品越會發生變化,因為價值更大。然後再匹配上從数字到物理的視角,有無幻覺的視角。以圖靈測試2.0為根基,加上這三個視角共同構成也約束了未來智能應用的發展路線。
這種路線的實現方式的具體體現就是我們經常說的Agent。
如果我們把智能的密度(原點是0),物理的程度(原點是0,代表純粹数字應用),幻覺有害度(原點是0,代表幻覺無害)畫一個坐標系,並把這個圖放在正中心位置排列,那在下面這個示意圖裡面,最頭部的是什麼呢?
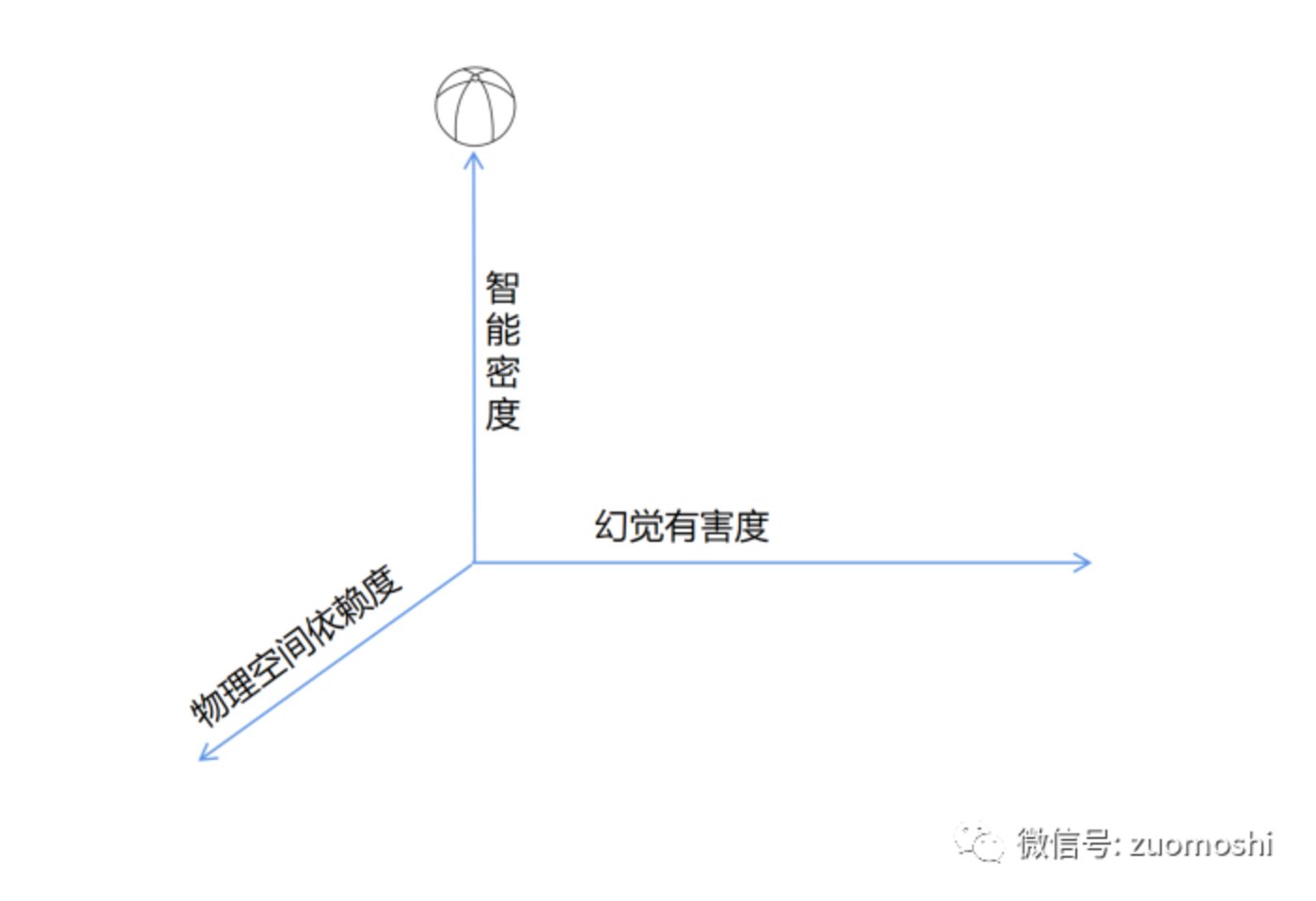
答案很可能是:遊戲,多維敘事類的遊戲。
Agent不是大模型的延伸而是新物種
通過圖靈測試2.0才能有真的agent。但需要注意的是agent不是大模型的延伸,而是一種新物種。做汽車發動機和做汽車怎麼都不是一回事,雖然汽車沒發動機根本跑不了。
只有Agent才能啟動AI的浪潮,而能啟動AI浪潮的Agent還不是別的簡單融合AI特徵的應用,而是智能原生型Agent。這種情況下,Agent不單是輸送智能到具體場景的管道。
智能原生應用的構圖:
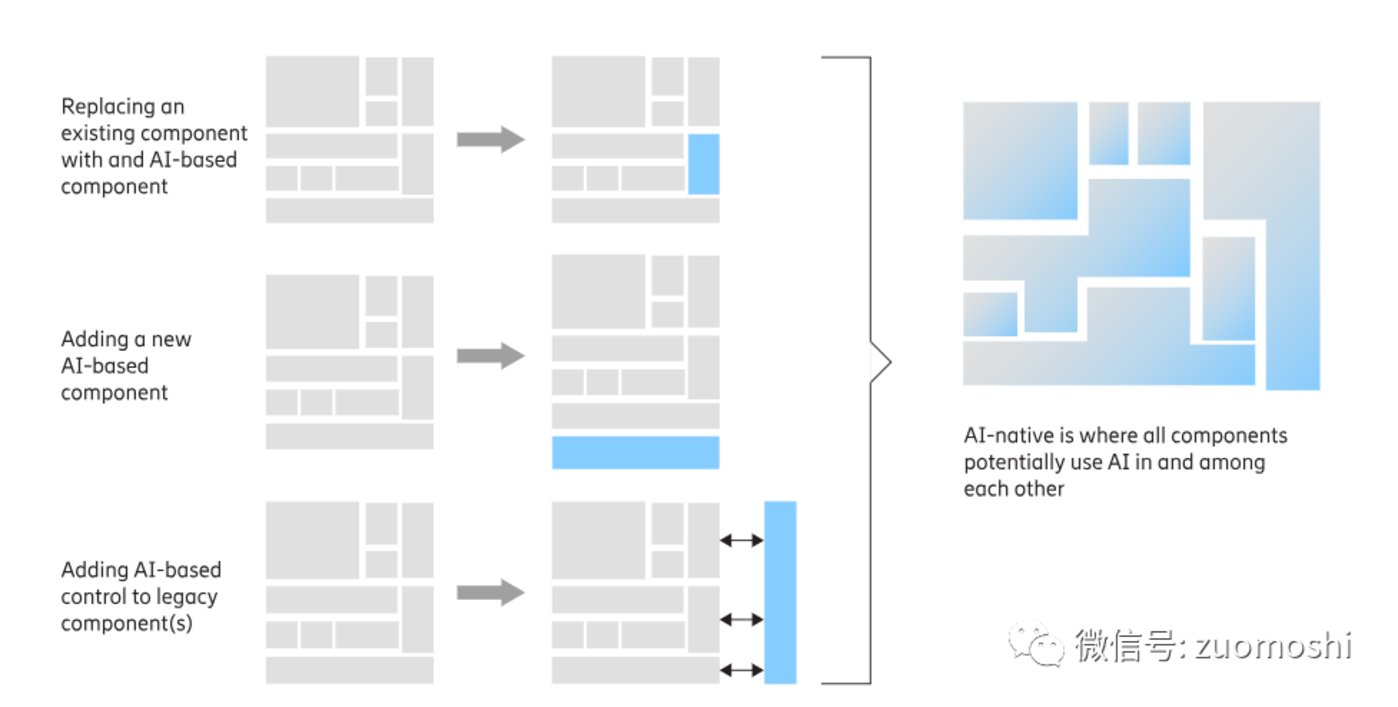
在這種思維模式,AI原生註定會被放到一個結構的中心位置:
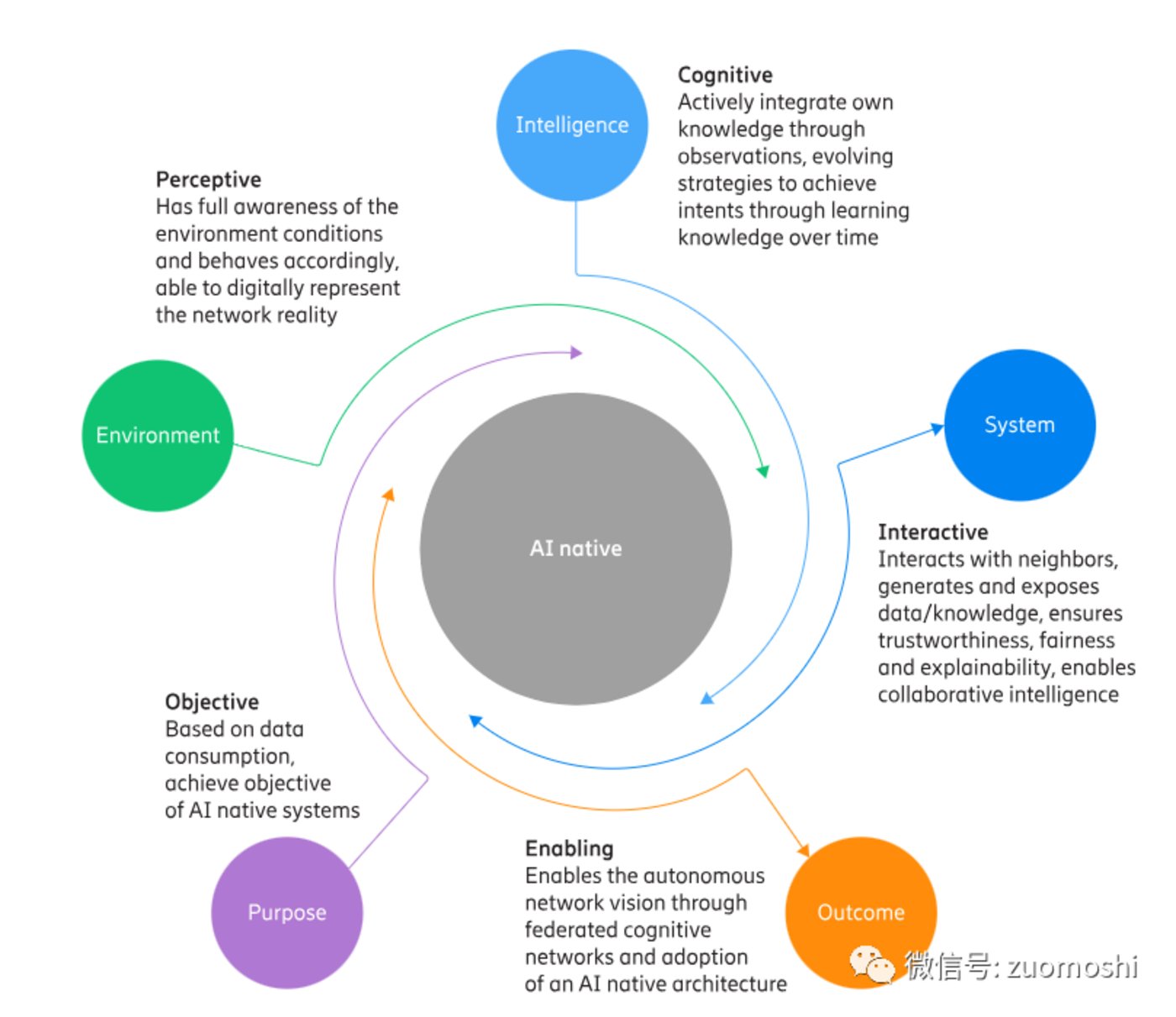
https://www.ericsson.com/en/reports-and-papers/white-papers/ai-native
在這裏大模型等扮演的是引擎的模式,通過不了圖靈測試2.0,那麼智能原生應用會很像用騾子拉的汽車。
通過了這個測試,再補上上面提到的感知、目標、反饋、使能環節,Agent才能真正成為新式通用計算的實現載體。只有通過這種測試才能一步步的把引擎換成蒸汽機、內燃機、渦輪增壓等。Agent範圍的擴大註定也就是智能一步步提高的過程。
現在能不能過圖靈測試2.0呢?
答案是過不了。所以才說現在的AI還不行。
我們可以調低標準,讓標準更垂直,只要範圍收縮的足夠窄,那所有測試都能過,但那沒意義。我們看下前面這個具體例子,就能理解上面整個邏輯鏈條:過不了圖靈測試2.0,成為不了智能原生應用的基座,只是憋在了AIGC這樣一個小池子里,所以現在的AI還不行。
假如你想開播了,但又不想自己上,而是希望做一個自己的数字代理或者說分身,那這個数字代理人真想取得效果都要搞定什麼呢?(取得效果是指有人願意看,有粉絲等)
首先是最基礎的產研部分:先打造自己的外殼,也就是形象要像那麼回事,然後給它匹配上看、聽、說、想的能力(計算機的輸入輸出、存儲和CPU...)。這裏面看、聽、說基本上是用過去十年反覆打磨的技術,比如圖像識別、語言識別、語音合成等,想的部分則要基於大模型了,它負責綜合各種輸入產生自己的輸出。當程序員把這些都連接起來,基本上就有了一個数字分身,它能基於觀眾的各種輸入做點反饋。但產品做到這裏基本上完成了手眼的部分,腦的部分屬於有了,但還不好使。這時候即使導入了最好的大模型,它也還是一個很傻的Bot,別說取得效果,基本上就沒人會看完任何一個直播段落。這時候在單純的單點技術上使勁內卷是沒前途的(包括大模型),那樣搞不定粉絲也搞不定留存,回報大致為0。
改善起來第一步肯定是希望能加入人格特徵,讓它的性格特徵和你更像,比如是不是對人友善、表達是不是犀利,也要社會一點:會說話能聯絡感情等。這時候要盡可能記住過去和某個人說過什麼。這部分不純粹是技術,但技術相關性還是很高,通常需要找找過去干過的老司機,純粹的干prompt估計搞不定(注1說的那課其實就是這個價值)。這步是個檻,搞定了算通過圖靈測試1.0,別人分不出到底是不是你了,但現在其實沒法徹底搞定這事,無邊界閑聊還行,限定到人格特徵上表現就沒想的那麼好。搞不定的情況下,會出現什麼結果呢?會看着有點智能有點像你的一個人,在那裡叨叨,但毫無特色和趣味性。能不能吸引到粉絲呢?這要看你到底播什麼了。我估計播動物世界沒準行,娛樂估計夠嗆。這是下面的話題,關鍵因素進一步從技術向產品偏移。
通過圖靈測試1.0的智能產品已經有用了,在這之前是純粹工具,在這之後就有點Agent的意思,但價值還沒想的那麼大。
通過圖靈測試1.0這樣的一個数字分身有什麼用呢?
它優點是信息吞吐量大,不知疲憊,人模人樣;壞處是智能還是不夠,做不出很好的性格、才藝、出眾的觀點、有趣的隨機應變等。那適合做什麼事呢?它適合做內容本身有趣,主播是配角的事。
那些事是這類的呢?比如播動物世界、講故事、播新聞,偶爾穿插點互動。這本質是一個更好用了的智能音箱。
這是在干什麼呢?是在縮減場景對智能的需求。智能供給不足就只能降級。
那理想狀況是什麼樣呢?
理想狀況是這個数字分身還要能接入實時的熱點,動態的生成要輸出的內容,比如圖片、視頻,然後做主播。這種熱點要匹配大家的關注點,要新穎,要匹配平台的規則,不單是正向的規則,還要把握好反向的尺度,否則會被抬走或者封殺。這部分會衍生非常多的細節工作,比如那個主題是現在主推的,這得跟着平台走才行,否則你權重不好它不推你,也白搭。對平台這是個智能對智能的過程,對受眾這是個綜合分析的過程,對創作這是個創意創新的過程。這事能幹了,算是通過圖靈測試2.0,一旦過了至少可以和人類二分天下。過不了,比如不管內容的時效或者不管平台熱點的捕捉,就都還是干半截活!是智能供給不足。這部分如果成功,那基本上可以有粉絲了。到這裏也才算是腦子長成,並且培養出了自己的風格。
假設這能做到了,就完了么?
也還沒有。這些都搞完了,主要解決了硅基智能和硅基智能的關係,相當於能夠比較匹配平台的規則和現實的熱點。
郭德綱捧人的主要方法就是反覆提這個人。你做主播如果有人拉扯顯然效果會更好。那和誰合作,怎麼合作還是需要人去做。把這個場景全覆蓋了,才算真正的你的代理。
上面說的可以總結成一張和自動駕駛類比的圖:
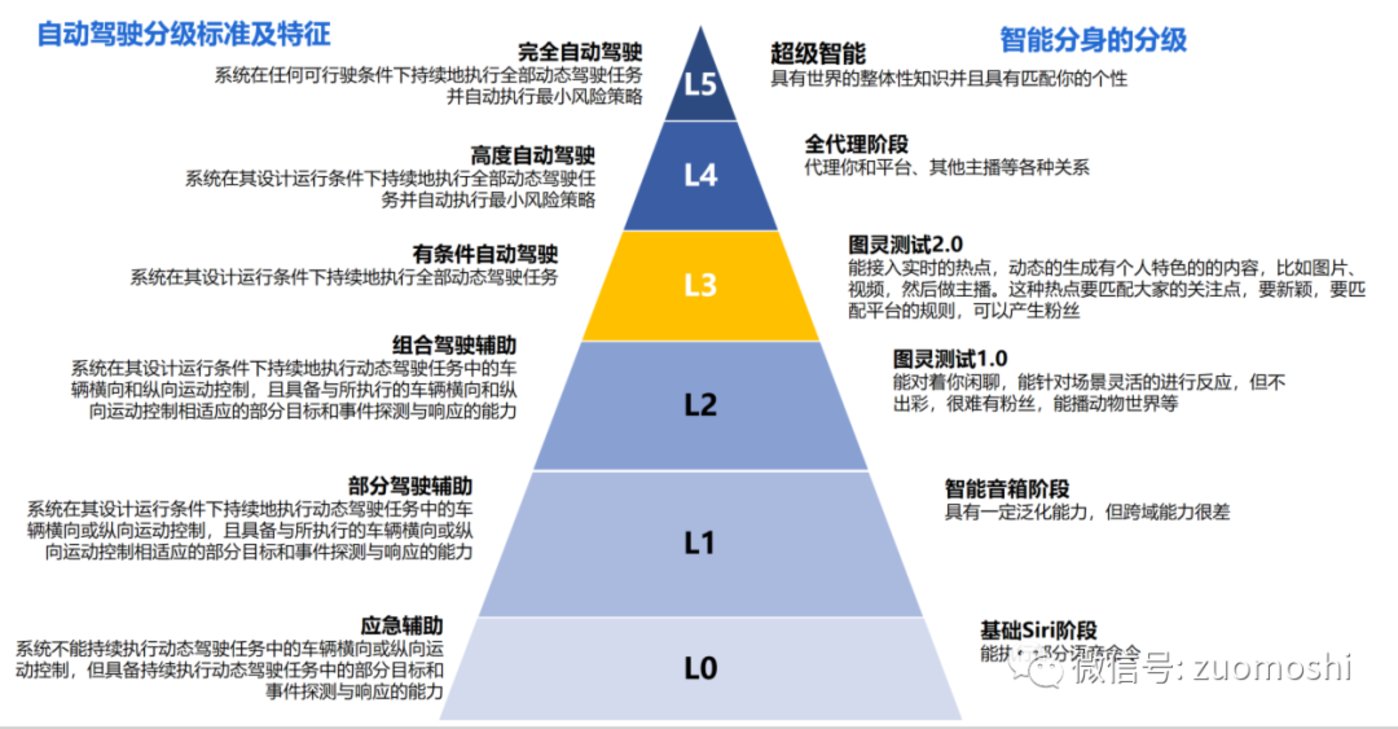
從這個視角看現在能完成的百分之十不到。更何況這隻是一個相對簡單的C端場景,B端場景比這個要複雜的多。
小結
AI這行當一直是這麼個狀態,一旦有一點突破,大家就歡欣鼓舞,然後預期就上去了,馬上能匹配這種預期的是什麼呢?是資本和營銷熱度。所以很快就會變的滿地都是以及看到非常多的高估值。但業務和這種預期的匹配則要難的多,但這裏才是行業的第一性。不同行業的這幾者間的速度差是不一樣的,互聯網的匹配速度其實最快,AI的匹配速度很可能是更像傳統軟件,次於互聯網,但快於消費產品。