所有語言











分享
即使人類犯錯,AI Agent也能快速學習,MIT、哈佛、UW提出新型強化學習方法HuGE
巴比特_学术头条658天前
原文來源:學術頭條

圖片來源:由無界 AI生成
為了教會 AI Agent 新技能,比如打開廚房櫥櫃,研究者通常採用強化學習方法。這是一種試錯過程,AI Agent 通過採取正確的行動接近目標而獲得獎勵。
在大多數情況下,人類專家需要精心設計獎勵函數,從而鼓勵 AI Agent 進行更多探索。隨着 AI Agent 的探索和嘗試,人類專家需要不斷更新這個獎勵函數。這一過程既耗時又低效,特別是在任務複雜、步驟繁多時,擴展起來更是十分困難。
日前,麻省理工學院(MIT)、哈佛大學和華盛頓大學的研究團隊開發了一種新型強化學習方法,這種方法不依賴專家設計的獎勵函數,而是利用來自許多非專家用戶的眾包反饋(crowdsourced feedback),來指導 AI Agent 達成學習目標。
儘管用戶眾包數據常常存在錯誤,這種新方法依然能夠讓 AI Agent 更快速地學習,這與其他嘗試使用非專家反饋的方法有所不同,而這些噪聲數據通常會讓其他方法失效。
此外,這種新方法支持異步收集反饋,使得全球各地的非專家用戶都可以參与到教導 AI Agent 的過程中。
MIT 電氣工程與計算機科學系助理教授、Improbable AI Lab 主任 Pulkit Agrawal 表示:“在設計 AI Agent 時,最耗時且具挑戰性的部分之一就是設定獎勵函數。當前,獎勵函數主要由專家設計,如果我們想讓機器人學習多種任務,這種方式是難以擴展的。我們的研究提出了一種方案,通過眾包來設計獎勵函數,並讓非專家參与提供有效反饋,從而擴大機器人的學習範圍。”
未來,這種方法可以幫助機器人在人們家中快速學習特定任務,而無需人們親自示範每項任務。機器人可以獨立探索,由眾包的非專家反饋引導其探索方向。
“在我們的方法中,獎勵函數不是直接告訴 AI Agent怎樣完成任務,而是指導它應該探索的方向。因此,即便人類監督存在一定的不準確性和噪聲,AI Agent仍然能夠進行有效探索,從而更好地學習,”Improbable AI Lab 研究助理、論文主要作者之一 Marcel Torne 解釋說。
即使接收的答案有誤,也能完成任務
一種收集強化學習用戶反饋的方法是向用戶展示 AI Agent 達到的兩種狀態的照片,並詢問哪種狀態更接近目標。例如,設想一個機器人的目標是打開廚房櫥櫃,其中一張照片可能显示它成功打開了櫥櫃,另一張則可能显示它打開了微波爐。用戶需要選擇表現更佳狀態的照片。
有些早期方法嘗試使用這種眾包形式的二元反饋,來優化 AI Agent 用以學習任務的獎勵函數。但問題在於,非專業人士容易出錯,這會導致獎勵函數變得極為混亂,以至於 AI Agent 可能無法達成目標。
Torne 指出:“實際上,AI Agent 會過分認真地對待獎勵函數,努力完美符合這一函數。因此,我們不直接優化獎勵函數,而是用它來指導機器人應探索的區域。”
研究團隊將這一過程分成兩個獨立部分,每部分由各自的算法驅動。他們將這種新型增強學習方法命名為人類引導探索(Human Guided Exploration,HuGE)。
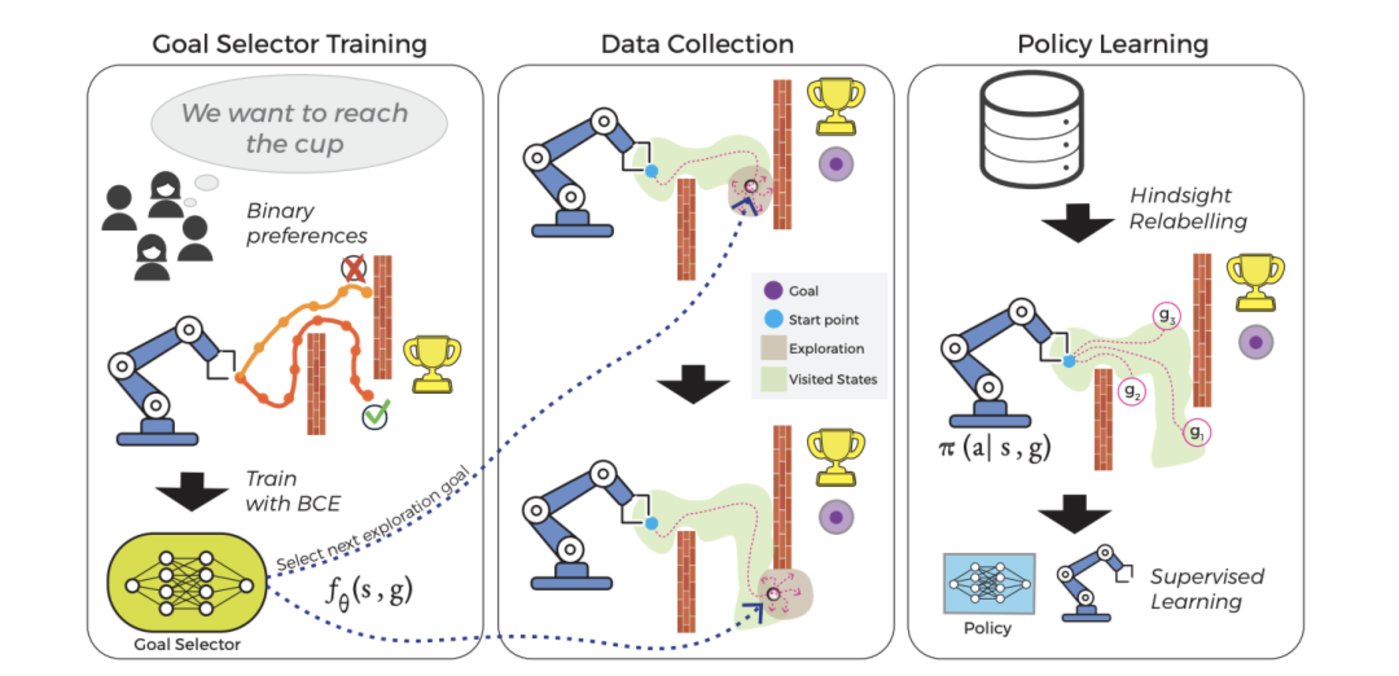
一方面,目標選擇算法會持續接收眾包的人類反饋並進行更新。這些反饋並非用作獎勵函數,而是用於指引 AI Agent 的探索方向。簡而言之,非專業用戶提供的指引就像一路撒下的“麵包屑”,逐漸引導 AI Agent 接近目標。
另一方面,AI Agent 自己也會進行探索,這一過程是自我監督的,由目標選擇器進行指導。它會收集自己嘗試的動作的圖像或視頻,隨後發送給人類,用於更新目標選擇器。
這樣做有助於縮小 AI Agent 需要探索的範圍,引導它前往更接近目標的有希望的區域。但如果暫時沒有反饋,或反饋遲遲未到,AI Agent 仍會繼續自行學習,儘管速度較慢。這種方式允許反饋的收集不那麼頻繁,也可以異步進行。
Torne 補充道:“探索過程可以自主、持續進行,因為它會不斷探索並學習新知識。當接收到更準確的信號時,它會以更明確的方式進行探索。它們可以按照各自的節奏運轉。”
由於反饋只是輕微地引導 AI Agent 的行為,即使用戶提供的答案有誤,AI Agent 最終也能學會如何完成任務。
更快的學習
研究團隊在一系列模擬和真實環境的任務中測試了這種方法。
例如,在模擬環境中,他們利用 HuGE 高效學習一系列複雜動作,比如按特定順序堆積積木或在迷宮中導航。

在真實環境的測試中,他們用 HuGE 訓練機器人手臂來繪製字母“U”和拾取放置物體。這些測試彙集了來自三大洲 13 個國家的 109 名非專業用戶的數據。

無論是在真實世界還是模擬實驗中,HuGE 都使得 AI Agent學習完成任務的速度比其他方法更快。
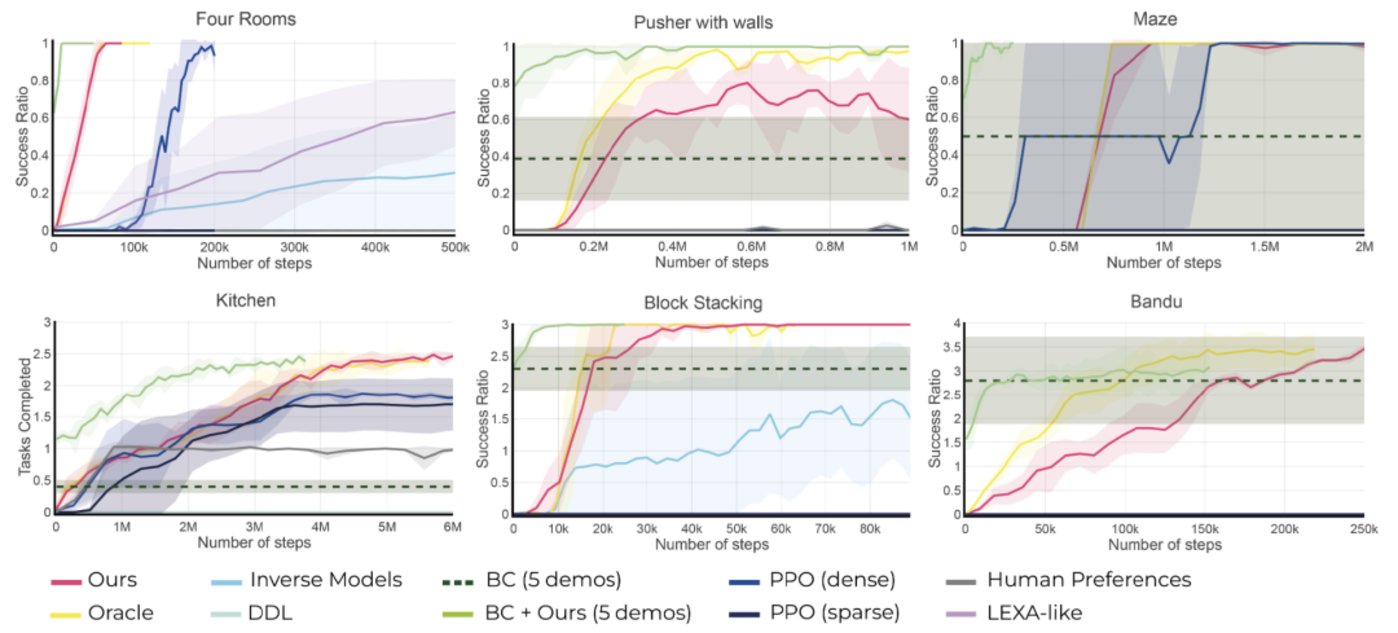
此外,與製作和標註的合成數據相比,非專家眾包的數據表現更佳。對非專家用戶而言,標註 30 張圖片或視頻不到兩分鐘就能完成。“這展示了這種方法在擴展應用方面的巨大潛力,”Torne 補充說。
在一項相關的研究中,研究團隊在最近的機器人學習會議上展示了他們如何改進 HuGE,使得 AI Agent 不僅能學習完成任務,還能自主地重置環境繼續學習。例如,如果 AI Agent 學會了打開櫥櫃,這種方法還能指導它關閉櫥櫃。
“現在我們能讓它在沒有人工干預的情況下完全自主學習,”他說。
研究團隊還強調,在這種以及其他學習方法中,確保 AI Agent與人類價值觀保持一致是至關重要的。
未來,研究團隊計劃進一步完善 HuGE,讓 AI Agent 能夠通過自然語言和與機器人的物理交互等更多方式學習。他們還對將這種方法應用於同時訓練多個 AI Agent 表示出了興趣。
參考鏈接