所有語言











分享
手機就能運行,1萬億訓練數據!StableLM-3B-4E1T來啦
巴比特_绘声绘影633天前
來源:AIGC開放社區
美東時間10月2日,著名開源平台Stability.ai在官網宣布,推出開源大語言模型StableLM-3B-4E1T。(開源地址:https://huggingface.co/stabilityai/stablelm-3b-4e1t)
據悉,Stable LM 3B是一款主要面向手機、筆記本等移動設備的基礎大語言模型,在保證性能的前提下,極大降低了算力資源的要求。
Stable LM 3B支持生成文本/代碼、總結摘要、數據微調、常識推理、解答數學題等功能,全局上下文長度為4096。(簡稱“Stable LM 3B”)

隨着ChatGPT的火爆出圈,全球掀起了轟轟烈烈的“大模型開發熱潮”。但多數模型皆需要耗費大量算力資源才能預訓練、微調,同時對開發的生成式AI應用的運行環境也有很高的要求。高通更是發布了專門針對移動端的生成式AI芯片,以解決算力問題。
Stability.ai希望通過開源Stable LM 3B,幫助那些沒有龐大算力資源的開發者,也能打造小巧精悍的生成式AI產品,可以安全、穩定地在移動端運行。
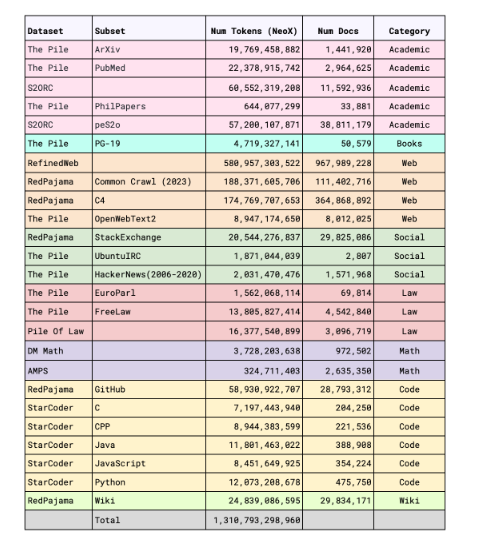
Stable LM 3B訓練數據集
雖然該模型只有30億參數,卻使用了一個包含文本、代碼、維基百科、ArXiv、圖書、C4等多種數據的1萬億tokens龐大的訓練數據集。
該數據集由多個開源的大規模數據集經過篩選混合而成,包括Falcon RefinedWeb、RedPajama-Data、The Pile以及 StarCoder等。
這使得Stable LM 3B以更少的資源,性能卻超越同等規模模型,甚至比一些70億、100億參數的大模型更強。
Stable LM 3B訓練流程
Stable LM 3B以bfloat16精度訓練972k起步,全局上下文長度為 4096,而不是像 StableLM-Alpha v2 那樣從 2048 到 4096 進行多階段提升。
Stability.ai使用了AdamW進行性能優化,並在前4800步使用線性預熱,然後採用餘弦衰減計劃將學習率降至峰值的4%。
早期的不穩定性歸因於在高學習率區域的長期停留。由於模型相對較小,沒有採用dropout。
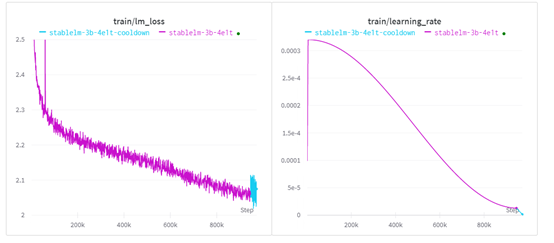
在訓練過程中,Stability.ai評估自然語言基準,並在學習率衰減計劃的尾聲階段,觀察到訓練帶來的穩步提升。基於這個原因,開發人員決定將學習率線性降低至0,類似於Zhai等人的做法,以期獲得更好的性能。
此外,在預訓練的初始階段依賴於 flash-attention API及其開箱即用的三角因果屏蔽支持。這迫使模型以類似的方式處理打包序列中的不同文檔。
在冷卻階段,Stability.ai在併發實驗中憑經驗觀察到樣本質量提高(即:減少重複)后,為所有打包序列重置 EOD 標記處的位置ID和注意掩碼。

硬件方面,StableLM-3B是在Stability AI的算力集群上訓練的。該集群包含256個NVIDIA A100 40GB顯卡。訓練開始於2023年8月23日,大約消耗了30天完成。
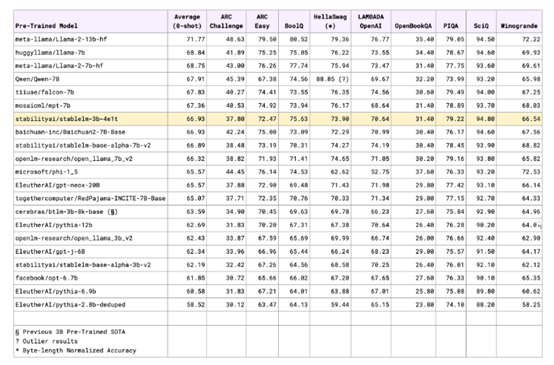
性能測試方面,StableLM-3B在零樣本的lm-evaluation-harness評估框架中,進行了性能測試。結果显示,性能完全不輸70億參數的模型,甚至比一些100億參數的更強。
本文素材來源Stability.ai官網,如有侵權請聯繫刪除